PowerHA完全手册(一)
目录
2.2.1. 安装PowerHA6.1(需要在所有节点上安装) 27
2.6.2. 修改syncd daemon的数据刷新频率 50
2.8.2. 同步脚本和用户的.profile等环境文件 58
6.1.1. 场景1:host1出现问题,但HACMP没有切换过来僵住了 108
6.1.2. 场景2:host1出现问题,HACMP切换过来,但僵住了 109
6.2.2. HACMP的too long报警广播的修正 110
7.1.2. 多service在同一网段并为磁盘心跳的配置 117
前言
自2008 年 4 月 02 日笔者在IBM DevelopWork网站首次发表《HACMP 5.X 完全手册》以来, 加上各网站的转载,应该已过了10万的阅读量,在此非常感谢大家的认可和支持。
转眼已经5年过去了,期间非常感谢不少同仁指出了该文的各种不足,并且HACMP已经改名为HACMP了,由于软件版本的更新和本人当时的技术水准有限,同时也存储不少同仁的希望,在原文基础上进行了补充和修订完善,也就有了本文。
正是由于AIX专家俱乐部的兴起,对AIX和HACMP的技术感兴趣的技术人员又更多了。因此选择本杂志作为原创发表,就是希望能对更多的同仁日常工作有所帮助。
此外,虽然本文号称“完全手册”,一是为了吸引眼球,二也只是相对于其他只谈安装配置的文档而言。由于HACMP现在已相当复杂,本文范围也主要关注于最常用的双节点,还望大家谅解。
即便如此,本文篇幅可能仍然较长,虽然也建议大家先通读一下,但实际使用使用时可根据具体目的按章节直接查阅操作。这是因为一方面本文所述操作笔者都加以验证过;一方面也是全中文,省得大家去查一大堆原版资料。希望能帮助大家在集成和运维HACMP的过程中节省精力、降低实施风险,这也是本文编写的初衷。同时还望那些被部分摘抄文章的同仁也能理解,你们都是笔者的老师,这里也一一谢过。
虽笔者端正态度,尽力认真编写,但由于能力有限,恐仍有错漏之处,还望众多同仁多多指正海涵,在此先行谢过。
1. 为什么需要PowerHA/HACMP
随着业务需求日益增加,IT的系统架构中核心应用必须一直可用,系统必须对故障必须有容忍能力,已经是现代IT高可用系统架构的基本要求。
10年前各厂商现有的UNIX服务器就已拥有很高的可靠性,在这一点上IBM的Power系列服务器表现尤为突出。但所有UNIX服务器均无法达到如原来IBM大型主机S/390那样的可靠性级别,这是开放平台服务器的体系结构和应用环境所决定的,这一点,即使科技发展到云计算的今天仍然如此。
因此,我们需要通过软件提供这些能力,同时这个软件还应该是经济有效的。它可以有效确保解决方案的任何组件的故障都不会导致用户无法使用应用程序及其数据。实现这一目标的方法是通过消除单一故障点消除或掩盖计划内和计划外停机。另外,保持应用程序高可用性并不需要特殊的硬件。
IBM高可用性集群软件--PowerHA/HACMP也就应运而生,即使到了今天 ,对比x86平台的linux、windows甚至包括其他UNIX操作系统的高可用性集群,至少从笔者20年的IT从业实际经历来看,IBM PowerHA/HACMP高可用性解决方案虽然复杂,需要更高水平工程师的精心维护,但的确相对更成熟更有效。
PowerHA的前身为HACMP ,或者说PowerHA 和 HACMP 这两个词对IBM来说可以互换使用。
基于这一点,也由于实际使用过程中PowerHA软件的名称、菜单名、日志等均仍为HACMP,因此后面论述时我们仍均称为PowerHA为HACMP,以免造成理解的困难。
2. PowerHA的版本
由于IBM对软件的整合,目前PowerHA其实不仅仅只包含之前的HACMP软件,我们先来看看下图:
 大家可以看到,我们通常的HACMP其实现在准确名称是 PowerHA SystemMirror ,它有2个平台4个主要大版本,for AIX ,i系统;企业版和标准版;企业版扩展了异地容灾相关的功能;而其他小版本,则是在其企业版和标准版基础之外的支持;比如最近比较热的PowerHA SystemMirror HyperSwap®的数据中心双活的解决方案 ,就是利用HyperSwap版本对存储DS8000容错的扩展支持来得以实现。
大家可以看到,我们通常的HACMP其实现在准确名称是 PowerHA SystemMirror ,它有2个平台4个主要大版本,for AIX ,i系统;企业版和标准版;企业版扩展了异地容灾相关的功能;而其他小版本,则是在其企业版和标准版基础之外的支持;比如最近比较热的PowerHA SystemMirror HyperSwap®的数据中心双活的解决方案 ,就是利用HyperSwap版本对存储DS8000容错的扩展支持来得以实现。
我们说的PowerHA pureScale,则是和类oracle RAC的IBMDB2 pureScale解决方案相配合的高可用性套件,不再是我们通常意义上的HACMP。
由于本文的重点为AIX的本地高可用性,因此除非特别声明,我们缺省说PowerHA时都是指PowerHA SystemMirror Standard的版本。
3. HACMP的工作原理
HACMP是High Availability Cluster Multi-Processing的缩写;也就是IBM公司在P系列 AIX操作系统上的高可靠集群软件,配置冗余,消除单点故障,保证整个系统连续可用性和安全可靠性。
HACMP是通过侦测主机及网卡的状况,搭配 AIX所提供的LVM等管理功能,在主机、网卡、硬盘控制卡或网络发生故障时,自动切换到另一套备用元件上重新工作; 若是主机故障还切换至备机上继续应用系统的运行。
作为双机系统的两台服务器同时运行HACMP软件;
u 两台服务器的备份方式大体有二种:
n 一台服务器运行应用,另外一台服务器做为备份
n 两台服务器除正常运行本机的应用外,同时又作为对方的备份主机;
u 两台主机系统在整个运行过程中,通过 "心跳线"相互监测对方的运行情况(包括系统的软硬件运行、网络通讯和应用运行情况等);
u 一旦发现对方主机的运行不正常(出故障)时,故障机上的应用就会立即停止运行,本机(故障机的备份机)就会立即在自己的机器上启动故障机上的应用,把故障机的应用及其资源(包括用到的IP地址和磁盘空间等)接管过来,使故障机上的应用在本机继续运行;
u 应用和资源的接管过程由HACMP软件自动完成,无需人工干预;
u 当两台主机正常工作时,也可以根据需要将其中一台机上的应用人为切换到另一台机(备份机)上运行。
4. HACMP术语:
为方便大家阅读,我们这里简单介绍一下HACMP 主要术语。它们可以分为拓扑组件和资源组件两类。
拓扑组件(Cluster topology)基本上是物理组件。它们包括:
· 节点(Nodes):运行AIX操作系统的Power服务器上的分区或微分区。
实际目前节点现分为2种,一个是服务器节点(Server 节点),运行核心服务和共享磁盘的应用的机器;一个是客户端节点(Client)节点,前台使用集群服务的应用的机器。比如中间件软件等无需共享磁盘安装在客户端节点的机器上,数据库软件安装在服务器节点的机器上。
像监控节点的信息收集程序clinfo就是只运行在客户节点上。而对于2个节点的集群,则简化掉这些分别,即节点为二合一。
· 网络(Networks):IP 网络和非 IP 网络
· 通信接口(Communication interfaces):以太网或令牌环网适配器
· 通信设备(Communication devices):RS232 或磁盘的心跳机制

拓扑组件示意图
资源组件(Cluster resources)是需要保持高可用性的逻辑实体。它们包括:
· 应用服务器(Application servers):它涉及应用程序的启动/停止脚本。
· 服务 IP 地址(Service IP labels / addresses):最终用户一般通过 IP 地址连接应用程序。这个 IP 地址映射到实际运行应用程序的节点。因为 IP 地址需要保持高可用性,所以它属于资源组。
· 文件系统(File systems):许多应用程序需要挂载文件系统。
· 卷组(Volume groups):许多应用程序需要高可用的卷组。
所有资源一起组成资源组实体。HACMP 把资源组当作单一单元处理。它会保持资源组高可用性。
 资源组件示意图
资源组件示意图
此外,还存在资源组有与其相关联的策略。这些策略包括:
1. 启动策略(Cluster startup):这决定资源组应该激活哪个节点。
2. 故障转移策略(Resource /Node failure):当发生故障时,这决定故障转移目标节点。
3. 故障恢复策略(Resource/Node recovery):这决定资源组是否执行故障恢复。
当发生故障时,HACMP 寻找这些策略并执行相应的操作。
5. 实验环境说明:
以双机互备中相对复杂的多业务网络的情况为例,其他类似设置可适当简化。
1) 机器一览表
节点机器名 | 操作系统 | 应用软件 | HA版本 |
host1 | AIX6.1.7 | ORACLE 11g | HA6.1.10 |
host2 | AIX6.1.7 | TUXEDO 11 | HA6.1.10 |
2) 磁盘和VG规划表
节点机器名 | 磁盘 | VG | VG MajorNumber |
host1 | hdisk2 | host1vg | 101 |
host2 | hdisk3 | host2vg | 201 |
3) 用户和组规划表
用户 | USERID | 组 | 组ID | 使用节点 |
orarunc | 610 | dba | 601 | host1 |
tuxrun | 301 | tux | 301 | host1 |
bsx1 | 302 | tux | 301 | host1 |
xcom | 401 | dba | 601 | host1 |
orarun | 609 | dba | 601 | host2 |
PP size:128M
节点机器名 | 逻辑卷 | 文件系统 | 大小(pp) | 所有者 | 用途 |
host1 | ora11runclv | /ora11runc | 40 | orarunc | ORACLE客户端软件 |
tux11runlv | /tux11run | 30 | tuxedo | Tuxedo软件 | |
bsx1lv | /bsx1 | 30 | bsx1 | 宝信MES应用程序 | |
xcomlv | /xcom | 30 | xcom | 宝信xcom通信软件 | |
host2 | ora11runlv | /ora11run | 60 | orarun | ORACLE数据库软件 |
oradatalv | /oradata | 80 | orarun | 数据库 |
5) 路由规划表
节点名 | 目的 | 路由 |
host1 | default | 10.2.100.254 |
10.2.200 | 10.2.1.254 | |
10.3.300 | 10.2.1.254 | |
host2 | default | 10.2.100.254 |
6) HACMP结构表
集群名: test_cluster
适配器名 | 功能 | 网络名 | 网络类型 | 属性 | 节点名 | IP地址 | MAC地址 |
host1_tty0 | heartbeat | host1_net_rs232 | rs232 | serial | host1 |
|
|
host1_l2_boot1 | boot1 | host2_net_ether_2 | ether | public | host1 | 10.2.2.1 |
|
host1_l1_boot1 | boot1 | host2_net_ether_1 | ether | public | host1 | 10.2.1.21 |
|
host1_l2_svc | Service | host1_net_ether_2 | ether | public | host1 | 10.2.200.1 |
|
host1_l1_svc1 | Service | host1_net_ether_1 | ether | public | host1 | 10.2.100.1 |
|
host1_l1_svc2 | Service | host1_net_ether_1 | ether | public | host1 | 10.2.101.1 |
|
host1_l2_boot2 | boot2 | host1_net_ether_2 | ether | public | host1 | 10.2.12.1 |
|
host1_l1_boot2 | boot2 | host1_net_ether_1 | ether | public | host1 | 10.2.11.1 |
|
host2_tty0 | heartbeat | host2_net_rs232 | rs232 | serial | host2 |
|
|
host2_l2_boot1 | boot1 | host2_net_ether_2 | ether | public | host2 | 10.2.2.2 |
|
host2_l1_boot1 | boot1 | host2_net_ether_1 | ether | public | host2 | 10.2.1.22 |
|
host2_l2_svc | service | host2_net_ether_2 | ether | public | host2 | 10.2.200.2 |
|
host2_l1_svc1 | service | host2_net_ether_1 | ether | public | host2 | 10.2.100.2 |
|
host2_l1_svc2 | service | host2_net_ether_1 | ether | public | host2 | 10.2.101.2 |
|
host2_l2_boot2 | boot2 | host2_net_ether_2 | ether | public | host2 | 10.2.12.2 |
|
host2_l1_boot2 | boot2 | host2_net_ether_1 | ether | public | host2 | 10.2.11.2 |
|
7) HACMP示意图
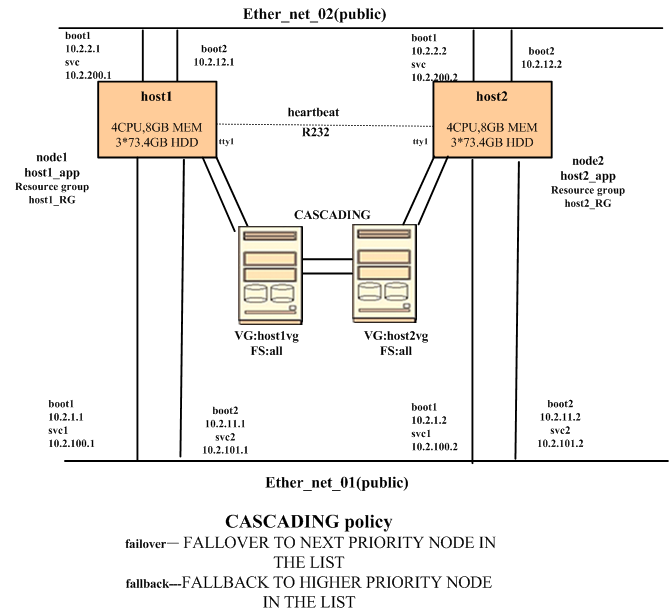
8) 实验环境示意图
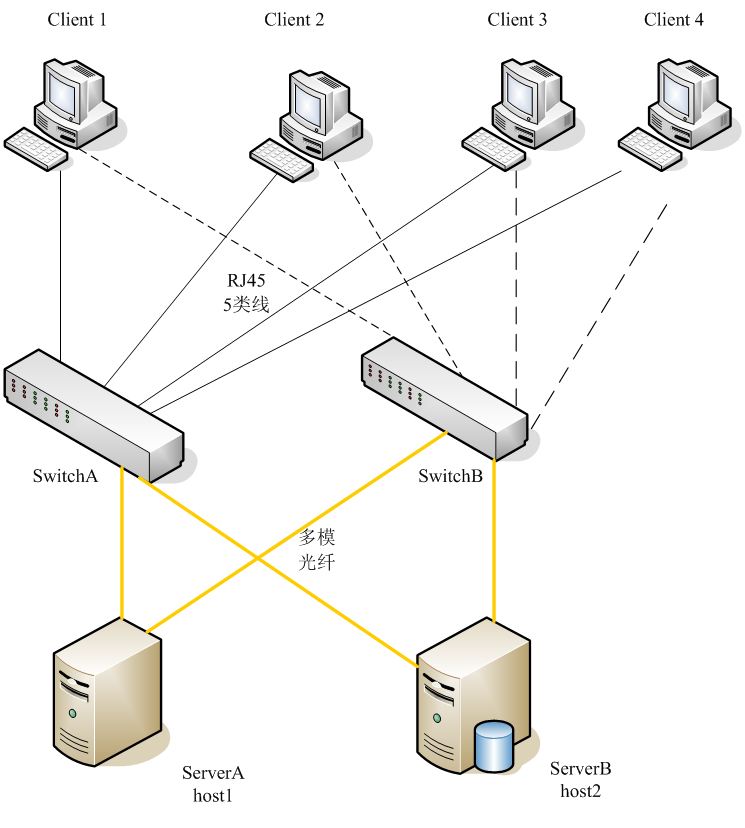
9) 应用脚本起停设计
Ø start_host1:
添加网关
运行start_host1_app
Ø stop_host1:
运行stop_host1_app
清理vg进程
Ø start_host2:
添加网关
运行start_host2_app
Ø stop_host2:
运行stop_host1_app
清理vg进程
Ø start_host1_app:
确认host2已启动
整理路由
启动主应用程序
启动通信程序
Ø stop_host1_app:
停通信程序
停应用主程序
清理路由
Ø start_host2_app:
如在host1机器上执行stop_host1_app
起Oracle数据库及listener
如在host1机器上执行start_host1
Ø stop_host2_app:
停数据库及listener
万事开头难,对于一个有经验的HACMP工程师来说,会深知规划的重要性,一个错误或混乱的规划将直接导致实施的失败和不可维护性。
HACMP实施的根本目的不是安装测试通过,而是在今后运行的某个时刻突然故障中,能顺利的发生自动切换或处理,使得服务只是短暂中断即可自动恢复,使高可用性成为现实。
2.1. 规划前的需求调研在做规划之前,或者说一个准备实施HACMP来保证高可用性的系统初步设计之前,至少需要调查了解系统的以下相关情况,这些都可能影响到HACMP的配置。
Ø 应用特点
1) 对负荷的需求,如CPU、内存、网络等特别是I/O的负载的侧重。
2) 对起停的要求,如数据库重起可能需要应用重起等等。
3) 对于自动化的限制,如重起需要人工判断或得到命令,需要在控制台执行。
Ø 网络状况和规划
包括网段的划分、路由、网络设备的冗余等等在系统上线前的状况和可提供条件,以及实施运行过程中可能出现的变更。
Ø 操作系统情况
目前IBM的HACMP除了AIX,还支持Linux。
目前新装机器都是AIX5.3,即使安装HA5.4也没有问题。但如果安装可能是在老机器上进行升级,需要仔细了解操作系统版本及补丁情况。
Ø 主机设计
1) 可能实施的机器网卡的数量,网卡是否只能是双口或更多。
2) 是否有槽位增加异步卡
3) 主机之间的距离,这影响到串口线的长度。
Ø 预计实施高可用性的情况
1) 希望实施HACMP的机器数量
2) 希望方式,如一备一,双机互备,一备多,环形互备等等。
2.2. PowerHA/HACMP版本确定
IBM HACMP 自从出了5.2 版本后, 到了5.205后比较稳定,并经过我们自己充分的测试(见测试篇)和实践证明(已有多个系统成功自动切换)。之前个人觉得HACMP5.3后变化较快快,功能增加多,稳定性不够,相当长时间还是一直推荐HA5.209。这也是本文出了第一版完全手册之后一直没有修订的原因之一。
随着Power主机和AIX的更新换代,名称也在变化,虽然目前最新版为PowerHA SystemMirror 7.1, 又增加了不少绚丽夺目的功能,但个人以为作为高可用性软件,其成熟度为第一要素,其稳定性有待进一步验证。而经过我们这2年来的充分实施经验,目前可以放心推荐版本为PowerHA 6.1的6.1.10及以上。
2.3. IP地址设计IP地址切换(IPAT)方式 有3种方式:
图1a,1b,和1c中描述了三个主要的IPAT配置场景。
u 第一个拓扑模式:IPAT via Replacement
在分开的子网中包含boot 和standby网卡。当集群服务启动的时候boot 地址被换成service 地址。尽管这种方式有效性强,但是在需要实现多服务IP地址的环境下这种方式是不可取的。集群的管理员不得不利用pre- 和 post-events 定制其环境建立额外的别名,
并且需要确认这些别名在下一次接管发生前被删除。

u 第二个拓扑模式:IPAT via Aliasing
HACMP 4.5 开始引入了IPAT via Aliasing 作为缺省的拓扑模式。在这种新的模式中,standby网卡的功能被另外一个boot网卡替换。子网需求的不同点是还需要一个另外的子网,每一个boot 网卡需要它自己的子网,并且任何service 或 persistent 的IP 将在其本身的子网上操作,所以一共三个子网。当集群服务启动并且需要service IP 的时候,boot IP 并不消失。这个设计和第一种是不同的,在同一个HACMP网络中有多个service IP存在并且通过别名来控制。

u 第三种模式:EthernetChannel(EC)
这种模式把底层的以太网卡藏到一个单一的“ent”接口之后。该模式不是对前述任何一种方式的替换,而是可以和前述的任一种模式共同存在。因为在每一个节点EC 都被配置成冗余方式,可以在HACMP中使用IP别名定义它们每一个作为单一网卡网络。因为在每个节点只有一个网卡被定义,所以只有两个子网,一个是用作 boot(每个节点的基本IP地址),另一个是用于提供高可用服务。

本文讨论实际工作中使用最多的为第2种:别名方式(IPAT via Aliasing),即使到今天,其使用仍然最为广泛,对交换机要求也最低。对于新型核心交换机和网络人员可紧密配合的,则推荐第3种,由于第3种更为简单,切换时间更短。但本文这里以第2种为主加以讨论。
这样设计时就需要注意以下事情:
1.
网段设计:
一个服务地址需要3个网段对应,boot地址网段不能和服务地址一致。避免网络变更造成的系统不可用,boot地址的网段不要和实际其他系统的网段一致。在网段比较紧张的地方,建议设计时询问网络人员。
举例来说,下面的地址将会由于网络变更后打通合一后可能造成冲突:
|
设计人 |
机器名 |
服务地址 |
boot1地址 |
boot2地址 |
|
张三 |
app1_db |
10.66.1.1 |
10.10.1.1 |
10.10.1.1 |
|
张三 |
app1_app |
10.66.1.2 |
10.10.2.2 |
10.10.2.2 |
|
李四 |
app2_db |
10.66.2.1 |
10.66.3.1 |
10.66.1.1 |
|
李四 |
app2_app |
10.66.2.2 |
10.66.3.2 |
10.10.1.2 |
|
王五 |
app3_db |
10.66.3.1 |
10.66.1.1 |
10.66.2.1 |
|
王五 |
app3_app |
10.66.3.2 |
10.66.1.2 |
10.10.2.2 |
2.
boot地址的设计:
不要和实际其他同网段机器的boot地址冲突,最好不同网段。即这个规划不能只考虑系统本身,还需要从同网段的高度考虑。
举例来说,下面的地址由于2个系统分开设计,同时开启将直接导致2个系统不可用。
boot地址的设计表1
|
设计人 |
机器名 |
服务地址 |
boot1地址 |
boot2地址 |
|
张三 |
app1_db |
10.66.3.1 |
10.10.1.1 |
10.10.1.1 |
|
张三 |
app1_app |
10.66.3.2 |
10.10.1.2 |
10.10.1.2 |
|
李四 |
app2_db |
10.66.3.11 |
10.10.1.1 |
10.10.1.1 |
|
李四 |
app2_app |
10.66.3.12 |
10.10.1.2 |
10.10.1.2 |
所以在设计时,我们建议boot地址的IP地址最后一段参照服务地址,这样虽然可记忆性不是很好,但即使设计在同一网段,也可以避免上述错误发生。更改设计如下:
boot地址的设计表2
|
设计人 |
机器名 |
服务地址 |
boot1地址 |
boot2地址 |
|
张三 |
app1_db |
10.66.3.1 |
10.10.1.1 |
10.10.1.1 |
|
张三 |
app1_app |
10.66.3.2 |
10.10.1.2 |
10.10.1.2 |
|
李四 |
app2_db |
10.66.3.11 |
10.10.1.11 |
10.10.1.11 |
|
李四 |
app2_app |
10.66.3.12 |
10.10.1.12 |
10.10.1.12 |
此外,如果是每个网卡多个网口,记得设计时必须注意同一网络的boot地址要分开到2块网卡,以保证真正的冗余。
2.4. 心跳设计配置HACMP的过程中,除了TCP/IP网络之外,您也可以在其它形式的网络上,如串行网络和磁盘总线上配置心跳网络。
1. TCP/IP网络
优点:要求低,不需要任何额外硬件或软件,即可实现。
缺点:占用IP地址,不能避免由于TCP/IP的软件问题导致HACMP崩溃,系统不可用。
2. 串口网络
优点:真正实现高可用性,不占用IP地址。
缺点:需要硬件支持,需要新增异步卡,而中低端的机器的插槽有限。
3. 磁盘心跳
优点:不占用插槽,磁盘总线上的心跳网络能够在TCP/IP网络资源有限的情况下提供额外的HACMP节点间的通信手段,并且能够防止HACMP节点之间由于 TCP/IP软件出现问题而无法相互通信。
缺点:需要操作系统和存储支持,如使用增强型卷组,此外对于I/O读写负荷高的应用,也需要慎用。
正如IBM红皮书所说,条件许可的情况下,强烈推荐使用串口网络,其次是磁盘心跳。不过我们也注意到HACMP7.1将不再支持串口心跳,而改为其他如SAN方式,效果有待进一步观察。
对于HACMP来讲,服务IP地址和磁盘VG、文件系统、应用服务器都是资源,如何规划需要根据实际情况来,包括以下内容:
资源组的数量即资源:一般情况下每台机器只要建立一个资源组即可,包括服务IP地址、应用服务器及VG。
现在不推荐具体确定VG里的文件系统,这是因为确定后,有可能造成有些新增文件系统不在HACMP的控制范围,结果是HACMP切换时由于这些文件系统没有unmount掉而导致切换失败。
资源组的策略:分failover(故障切换)和fallback(回切)等。一般选缺省,当然你可以根据具体情况修正,如oracle 10g RAC的并发VG资源组的选择就不一样。
2.5.1.磁盘及VG设计虽然实际上HACMP是靠PVID来认磁盘的,但集群的机器上磁盘顺序不一,磁盘对应不一致会造成某种混乱。以致于安装配置和维护时很容易产生各种人为错误,所以我们强烈建议机器上看到的磁盘和VG名称都一一对应,此外VG 的MajorNumber也需要预先设计规划,以免不一致。同时新的AIX6.1已很好提供了修改hdisk号的rendev 命令,以前这样的烦恼也就迎刃而解了。
2.5.2.用户及组设计HA要求所有切换需要用到的用户必须所有节点对应,ID完全相同,用户运行的环境变量完全相同,即当系统切换时,对使用该用户的程序用户即组设置没有区别的。
如某系统的host2上oracle用户为orarun,host1上的orarun必须为切换保留,ID均为209,host1上平时用的oracle用户就设为orarunc。
2.5.3.逻辑卷和文件系统设计HACMP要求切换相关的文件系统和lv不能重名,如host2上oracle软件目录为/ora11run,host1上的/ora11run必须为切换保留,改为/ora11runc。
此外,集群下相关的文件系统和lv,在各个节点主机的定义也需要一致,如/etc/filesystems里是一致的,这个通过importvg或HACMP的C-SPOC来保证。
2.5.4.路由设计对于有通信需求的主机,很可能对路由有一定要求,如本次实验环境,就有2个网段走的不是缺省路由,需要设计清楚,最后在起停脚本实现。
2.5.5.应用脚本设计我们这里说的应用,是包括数据库在内除OS和HACMP之外的所有程序,对于应用程序的起停顺序和各种要求,都需要预先和应用人员加以沟通,并预先设计伪码,最终编写脚本实现。
第二部分--安装配置篇2.1. 准备2.1.1.安装前提 1) 操作系统版本要求:实验实际为AIX6.1.10,实际HACMP6.1 要求AIX5.3.9和AIX6.1.2,具体安装时可查看以下安装版本的《High Availability Cluster Multi-Processing for AIX Installation Guide》Prerequisites一节。
2) 系统参数要求作为集群的各个节点机,我们建议各个参数最好完全一致,需要注意的参数有:
1. 异步I/O 服务进程配置(Asynchronous I/O servers)
2. 用户最大进程数
3. 系统时间
4. 用户缺省的limits参数
5. 其他可能影响应用的参数
3) 环境要求此时,没有建立任何HACMP占用设计ID相关用户和组,同样也没有建立VG和文件系统,包括名称冲突文件系统和lv和Major numver冲突的VG。
Ø 用户和组确认
目的:确认没有和设计中ID冲突的用户,否则需要调整。
[host1][root][/]lsuser -a id ALL
root id=0
daemon id=1
bin id=2
sys id=3
adm id=4
uucp id=5
……
[host2][root][/]>lsuser -a id ALL
root id=0
daemon id=1
……
Ø 文件系统确认
目的:确认没有和设计名称相冲突的文件系统,否则需要调整。
[host1][root][/]>df -k
Filesystem 1024-blocks Free %Used Iused %Iused Mounted on
/dev/hd4 524288 487820 7% 3276 3% /
/dev/hd2 7077888 1868516 74% 91290 18% /usr
/dev/hd9var 524288 458364 13% 991 1% /var
/dev/hd3 917504 826700 10% 120 1% /tmp
/dev/hd1 655360 524856 20% 291 1% /home
/proc - - - - - /proc
/dev/hd10opt 1179648 589072 51% 11370 8% /opt
[host2][root][/]>df -k
…..
4) 安装包要求:
RSCT 3.1.2.0 或更高版本。lslpp -l|grep rsct
以下的包也是必须要安装的:(脚本可直接拷贝运行)
lslpp -l rsct.*
lslpp -l bos.adt.lib
lslpp -l bos.adt.libm
lslpp -l bos.adt.syscalls
lslpp -l bos.net.tcp.client
lslpp -l bos.net.tcp.server
lslpp -l bos.rte.SRC
lslpp -l bos.rte.libc
lslpp -l bos.rte.libcfg
lslpp -l bos.rte.libcur
lslpp -l bos.rte.libpthreads
lslpp -l bos.rte.odm
显示确认结果:
[host1][root][/]>lslpp -l rsct.*
Fileset Level State Description
----------------------------------------------------------------------------
Path: /usr/lib/objrepos
rsct.basic.hacmp 3.1.2.0 COMMITTED RSCT Basic Function (HACMP/ES
Support)
rsct.basic.rte 3.1.2.0 COMMITTED RSCT Basic Function
rsct.basic.sp 3.1.2.0 COMMITTED RSCT Basic Function (PSSP
Support)
rsct.compat.basic.hacmp 3.1.2.0 COMMITTED RSCT Event Management Basic
Function (HACMP/ES Support)
rsct.compat.basic.rte 3.1.2.0 COMMITTED RSCT Event Management Basic
Function
rsct.compat.basic.sp 3.1.2.0 COMMITTED RSCT Event Management Basic
Function (PSSP Support)
rsct.compat.clients.hacmp 3.1.2.0 COMMITTED RSCT Event Management Client
Function (HACMP/ES Support)
[host2][root][/]>lslpp -l rsct.*
……
如果是光盘,请插入光盘 ,输入smitty install_latest
Install Software
Type or select values in entry fields.
Press Enter AFTER making all desired changes.
[Entry Fields]
* INPUT device / directory for software /dev/cd0
* SOFTWARE to install [_all_latest]
…..
ACCEPT new license agreements? yes
Preview new LICENSE agreements? no
如果是安装盘拷贝,请进入cd installp/ppc目录,smitty install_latest
Install Software
Type or select values in entry fields.
Press Enter AFTER making all desired changes.
[Entry Fields]
* INPUT device / directory for software .
* SOFTWARE to install [_all_latest]
…..
ACCEPT new license agreements? yes
Preview new LICENSE agreements? no
安装结束后,会报failed,请检查
cluster.doc.en_US.pprc.pdf
cluster.es.cgpprc.rte
cluster.es.pprc.cmds
cluster.es.spprc.*
cluster.es.sr.*
cluster.es.svcpprc.*
cluster.xd.*
glvm.rpv.*
包以外,所有的HACMP的包都要安装
2.2.2.打补丁注意,请不要忽略给HACMP打补丁这一步骤。其实对HACMP来说,补丁是十分重要的。很多发现的缺陷都已经在补丁中被解决了。当严格的按照正确步骤安装和配置完HACMP的软件后,发现takeover 有问题,IP接管有问题,机器自动宕机等等千奇百怪的问题,其实大都与补丁有关。所以一定要注意打补丁这个环节。如为HACMP 6110 或 IV42930以上
Apar: IV42930
LATEST HACMP FOR AIX R610 FIXES SP11 MAY 2013 。
smitty install_latest,全部安装
[host1][root][/soft_ins/ha61/patch]>ls
.toc
cluster.es.cspoc.dsh.5.2.0.21.bff
cluster.adt.es.client.include.5.2.0.3.bff ……
安装结束后,仍会报failed,检查
glvm.rpv.*
cluster.xd.glvm
cluster.es.tc.*
cluster.es.svcpprc.*
cluster.es.sr.rte.*
cluster.es.spprc.*
cluster.es.pprc.*
cluster.es.genxd.*
cluster.es.cgpprc.*
没装上外,其他都已安装上。
补丁可在IBM网站下载:

重启机器
注:记住一定要重起机器,否则安装将无法正常继续。
2.2.3.安装确认1) 确认inittab:
egrep -i "hacmp" /etc/inittab
hacmp:2:once:/usr/es/sbin/cluster/etc/rc.init >/dev/console 2>&1
在HACMP 6.1版本中,我们可以看到inittab非常简化,将所有HACMP需要开机启动相关进程的工作,全部归入一个脚本/usr/es/sbin/cluster/etc/rc.init来运行。如果你查看/etc文件/inittab文件 就会发现安装完HACMP后,仅添加了一行:
hacmp:2:once:/usr/es/sbin/cluster/etc/rc.init >/dev/console 2>&1 。
2) 确认安装和补丁包:(关键为cluster.es.server.rte)lslpp -l cluster.*
Fileset Level State Description
----------------------------------------------------------------------------
Path: /usr/lib/objrepos
…..
cluster.es.server.rte 6.1.0.10 COMMITTED ES Base Server Runtime
……
3) 确认clcomdES已启动lssrc -s clcomdES
Subsystem Group PID Status
clcomdES clcomdES 4128974 active
总的来说,配置前的准备必不可少,这一步还要仔细小心,准备不充分或有遗漏以及这步的细节疏忽会导致后面的配置出现网卡、磁盘找不到等现象。将会直接导致后面的配置失败。
2.3.1.修改.rhosts修改确认每台机器/.rhosts为:
[host1][root]vi /.rhosts
host1
host1_l2_boot1
host1_l1_boot1
host1_l2_svc
host1_l1_svc1
host1_l1_svc2
host1_l2_boot2
host1_l1_boot2
host2
host2_l2_boot1
host2_l1_boot1
host2_l2_svc
host2_l1_svc1
host2_l1_svc2
host2_l2_boot2
host2_l1_boot2
注意权限修改:
chmod 644 /.rhosts
在HACMP 6.1中 为了安全起见,不再使用/.rhosts 文件来控制两台机器之间的命令和数据交换,使用 /usr/es/sbin/cluster/etc/rhosts 文件来代替 /.rhosts 文件的功能。
注意:如果两个节点间的通讯发生了什么问题,可以检查rhosts 文件,或者编辑rhosts文件加入两个节点的网络信息。为方便配置期间检查发现问题,配置期间我们让/.rhosts和HACMP的rhosts一致。
2.3.2.修改/etc/hosts
修改确认每台机器/etc/hosts为:
127.0.0.1 loopback localhost # loopback (lo0) name/address
10.2.2.1 host1_l2_boot1
10.2.1.21 host1_l1_boot1 host1
10.2.200.1 host1_l2_svc
10.2.100.1 host1_l1_svc1
10.2.101.1 host1_l1_svc2
10.2.12.1 host1_l2_boot2
10.2.11.1 host1_l1_boot2
10.2.2.2 host2_l2_boot1
10.2.1.22 host2_l1_boot1 host2
10.2.200.2 host2_l2_svc
10.2.100.2 host2_l1_svc1
10.2.101.2 host2_l1_svc2
10.2.12.2 host2_l2_boot2
10.2.11.2 host2_l1_boot2
注:正式配置之前,主机名落在boot地址上,待配置完成后将改为服务IP地址上。
确认:
[host1][root][/]>rsh host2 date
Wed Sep 11 15:46:06 GMT+08:00 2013
[host2][root][/]>rsh host1 date
Wed Sep 11 15:46:06 GMT+08:00 2013
[host1][root][/]#rsh host1 ls -l /usr/es/sbin/cluster/etc/rhosts
-rw------- 1 root system 237 Sep 11 15:45 /usr/es/sbin/cluster/etc/rhosts
[host1][root][/]#rsh host2 ls -l /usr/es/sbin/cluster/etc/rhosts
-rw------- 1 root system 237 Sep 11 15:45 /usr/es/sbin/cluster/etc/rhosts
2.3.3.添加共享vg:
[host1][root][/]>lspv
hdisk0 00c1fe1f0215b425 rootvg active
hdisk1 00c1fe1f8d700839 rootvg active
hdisk2 none none
hdisk3 none none
smitty vg -> Add a Volume Group
[host1][root][/]>lspv
。。。
hdisk2 00f6f1569990a1ef host1vg active
hdisk3 00f6f1569990a12c host2vg active
2.3.4.建立文件系统
由于后面需要修改loglv,必须建立文件系统才会有loglv,所以需要先建立在host1vg 上的 /ora11runc和host2vg上的/ora11run的JFS2文件系统,其他文件系统可在实施中的配置中2边同时添加。
smitty lv ->Add a Logical Volume,注意选择JFS2
smitty fs-> Enhanced Journaled File Systems -> Add a Journaled File System
[host1][root][/]>lsfs
Name Nodename Mount Pt VFS Size Options Auto Accounting
...
/dev/ora11runlv -- /ora11run jfs2 15728640 rw no no
/dev/ora11runclv -- /ora11runc jfs2 10485760 rw no no
...
2.3.5.修改loglv
这一步有2个目的,一是避免两边loglv重名,二是规范loglv的取名,使它看起来更清楚明了。
host1vg (host2vg也要修改)
1) 察看
[host1][root][/]>varyonvg host1vg
[host1][root][/]>lsvg -l host1vg
host1vg:
LV NAME TYPE LPs PPs PVs LV STATE MOUNT POINT
ora11runclv jfs2 40 40 1 closed/syncd /ora11runc
loglv02 jfs2log 1 1 1 closed/syncd N/A
umount vg上所有fs
如 umount /ora11runc
2) 修改loglv名称
[host1][root][/]> chlv -n host1_loglv loglv02
0516-712 chlv: The chlv succeeded, however chfs must now be
run on every filesystem which references the old log name loglv02.
[host1][root][/]>lsvg -l host1vg
host1vg:
LV NAME TYPE LPs PPs PVs LV STATE MOUNT POINT
ora11runclv jfs2 40 40 2 closed/syncd /ora11runc
host1_loglv jfs2log 1 1 1 closed/syncd N/A
[host1][root][/]> vi /etc/filesystems
将"log = /dev/loglv02"的改为"log =/dev/host1_loglv"
确认:
[host1][root][/]>mount /ora11runc
在每台机器上都运行以下脚本(实际可以copy以下脚本到文本编辑器替换成你实际的vg)
varyoffvg host1vg
varyoffvg host2vg
exportvg host1vg
exportvg host2vg
chdev -l hdisk2 -a pv=yes
chdev -l hdisk3 -a pv=yes
importvg -V 101 -n -y host1vg hdisk2
varyonvg host1vg
chvg -an host1vg
importvg -V 201 -n -y host2vg hdisk3
varyonvg host2vg
chvg -an host2vg
varyoffvg host1vg
varyoffvg host2vg
确认:
[host1][root][/]>lspv
。。。
hdisk2 00f6f1569990a1ef host1vg
hdisk3 00f6f1569990a12c host2vg
[host2][root][/]>lspv
。。。
hdisk2 00f6f1569990a1ef host1vg
hdisk3 00f6f1569990a12c host2vg
[host2][root][/]>varyong host1vg;varyong host2vg
[host2][root][/]>lsfs
Name Nodename Mount Pt VFS Size Options Auto Accounting
...
/dev/ora11runclv -- /ora11runc jfs2 10485760 rw no no
/dev/ora11runlv -- /ora10run jfs2 15728640 rw no no
2.3.7.修改网络参数及IP地址
由于AIX会cache路由配置,因此需要修改一些参数:
routerevalidate
[host2][root][/]no -po routerevalidate=1
Setting routerevalidate to 1
Setting routerevalidate to 1 in nextboot file
确认:
[host2][root][/]#no -a|grep routerevalidate
routerevalidate = 1
按照规划,2台机器修改IP地址 ,smitty tcpip,最终为
[host1][root][/]>netstat -in
Name Mtu Network Address Ipkts Ierrs Opkts Oerrs Coll
en0 1500 10.2.1 10.2.1.21 2481098 0 164719 0 0
en0 1500 link#2 2.f8.28.3a.82.3 2481098 0 164719 0 0
en1 1500 10.2.2 10.2.2.1 142470 0 10 0 0
en1 1500 link#4 2.f8.28.3a.82.5 142470 0 10 0 0
en2 1500 10.2.11 10.2.11.1 22 0 20 0 0
en2 1500 link#3 2.f8.28.3a.82.6 22 0 20 0 0
en3 1500 10.2.12 10.2.12.1 0 0 4 0 0
en3 1500 link#5 2.f8.28.3a.82.7 0 0 4 0 0
lo0 16896 127 127.0.0.1 1335968 0 1335969 0 0
lo0 16896 ::1%1 1335968 0 1335969 0 0
lo0 16896 link#1 1335968 0 1335969 0 0
[host1][root][/]>netstat -i
Name Mtu Network Address Ipkts Ierrs Opkts Oerrs Coll
en0 1500 10.2.1 host1_l1_boot1 2481124 0 164734 0 0
en0 1500 link#2 2.f8.28.3a.82.3 2481124 0 164734 0 0
en1 1500 10.2.2 host1_l2_boot1 142476 0 10 0 0
en1 1500 link#4 2.f8.28.3a.82.5 142476 0 10 0 0
en2 1500 10.2.11 host1_l1_boot2 22 0 20 0 0
en2 1500 link#3 2.f8.28.3a.82.6 22 0 20 0 0
en3 1500 10.2.12 host1_l2_boot2 0 0 4 0 0
en3 1500 link#5 2.f8.28.3a.82.7 0 0 4 0 0
lo0 16896 127 loopback 1335968 0 1335969 0 0
lo0 16896 ::1%1 1335968 0 1335969 0 0
lo0 16896 link#1 1335968 0 1335969 0 0
[host2][root][/]>netstat -in
[host2][root][/]#netstat -in
Name Mtu Network Address Ipkts Ierrs Opkts Oerrs Coll
en0 1500 link#2 2.f8.29.0.6.4 1013585 0 63684 0 0
en0 1500 10.2.1 10.2.1.22 1013585 0 63684 0 0
en1 1500 link#4 2.f8.29.0.6.5 141859 0 12 0 0
en1 1500 10.2.2 10.2.2.2 141859 0 12 0 0
en2 1500 link#3 2.f8.29.0.6.6 5 0 20 0 0
en2 1500 10.2.11 10.2.11.2 5 0 20 0 0
en3 1500 link#5 2.f8.29.0.6.7 2 0 6 0 0
en3 1500 10.2.12 10.2.12.2 2 0 6 0 0
lo0 16896 link#1 515177 0 515177 0 0
lo0 16896 127 127.0.0.1 515177 0 515177 0 0
lo0 16896 ::1%1 515177 0 515177 0 0
[host2][root][/]#netstat -i
Name Mtu Network Address Ipkts Ierrs Opkts Oerrs Coll
en0 1500 link#2 2.f8.29.0.6.4 1013619 0 63696 0 0
en0 1500 10.2.1 host2_l1_boot1 1013619 0 63696 0 0
en1 1500 link#4 2.f8.29.0.6.5 141876 0 12 0 0
en1 1500 10.2.2 host2_l2_boot1 141876 0 12 0 0
en2 1500 link#3 2.f8.29.0.6.6 5 0 20 0 0
en2 1500 10.2.11 host2_l1_boot2 5 0 20 0 0
en3 1500 link#5 2.f8.29.0.6.7 2 0 6 0 0
en3 1500 10.2.12 host2_l2_boot2 2 0 6 0 0
lo0 16896 link#1 515199 0 515199 0 0
lo0 16896 127 loopback 515199 0 515199 0 0
lo0 16896 ::1%1 515199 0 515199 0 0
2.3.8.编写初步启停脚本mkdir -p /usr/sbin/cluster/app/log
[host1][root][/usr/sbin/cluster/app]>ls
start_host1 start_host2 stop_host1 stop_host2
#start_host1
banner start host1
route delete 0
route add 0 10.2.1.254
banner end host1
exit 0
# stop_host1
banner stop host1
banner end host1
exit 0
# start_host2
banner start host2
route delete 0
route add 0 10.2.1.254
banner end start host2
#stop_host2
banner stop host2
banner end host2
exit 0
记得chmod 755 start* stop*赋予文件执行权限。
编写完成后记得拷贝到另一节点:
[host1][root][/usr/sbin/cluster]>rcp -rp app host2:/usr/sbin/cluster
注意:在两个节点要保证hosts 和 启动/停止脚本要一样存在,并具有执行权限,否则集群自动同步的时候会失败,同时网关在启动脚本里要增加。
2.3.9.配置 tty 心跳 网络/磁盘心跳
Ø 串口线心跳(两边都要增加)
. smitty tty->Change / add a TTY->rs232->sa->port number : 0
确认
host1: cat /etc/hosts>/dev/tty0
host2:cat</dev/tty0
在host2可看到host1上/etc/hosts的内容。
同样反向检测一下。
Ø 磁盘心跳
1. 建立1个共享盘 5G足够
2. 两边用chdev -l hdiskpower0 -a pv=yes 先将两边的盘符认出来,这样之后系统才能自动扫到磁盘
确认
[host1][root][/]lspv
...
hdisk5 00f6f1560ff93de3 None
[host2][root][/]lspv
...
hdisk5 00f6f1560ff93de3 None
以前的绝大多数配置HACMP,没有明确的这个阶段,都是先两边各自配置用户,文件系统等,然后通过修正同步来配置,这样做的好处是不受任何约束;但坏处脉络不清晰,在配置和日后使用时不能养成良好习惯,必然造成两边的经常不一致,使得停机整理VG这样各节点同步的事情重复劳动,并且很容易疏忽和遗漏。
这一步的目的是为了配置一个和应用暂时无关的“纯粹”的HACMP,方便检测和下一步的工作,可以理解为“不带应用的HACMP配置”。
此外,虽然HACMP配置分标准配置(Standard)和扩充配置(Extend)两种,但我个人还是偏好扩充配置,使用起来步骤更清晰明了,容易掌控。而且完全用标准配置则复杂的做不了,简单的却可能做错,不做推荐。
2.4.1.创建集群smitty hacmp->Extended Configuration
->Extended Topology Configuration
->Configure an HACMP Cluster
->Add/Change/Show an HACMP Cluster
2.4.2. 增加节点
smitty hacmp-> Extended Configuration
->Extended Topology Configuration
->Configure HACMP Nodes
->Add a Node to the HACMP Cluster
注:此处的Node Name需要手动输入,为机器主机名。Communication Path to Node可以通过F4选择为:主机名的boot地址。
同理可以添加第二个节点
2.4.3.创建IP网络及接口
smitty hacmp-> Extended Configuration
-> Extended Topology Configuration
->Configure HACMP Networks
->Add a Network to the HACMP Cluster->ether
其中Enable IP Address Takeover via IP Aliases [Yes]
此选项决定了HACMP的IP切换方式,但值得一提的是只有“boot1/boot”、“boot2/standby”、“svc/service”三个IP分别为三个不同网段时必须选用IP Aliases方式。
如果““boot1/boot”、“boot2/standby”其中一个与“svc/service”为同一个网段时必须选用IP Replace方式,则此选项应选“NO”。
同样完成net_ether_02网络的创建。
向这些网络添加boot地址网络接口:
smitty hacmp-> Extended Configuration
-> Extended Topology Configuration
->Configure HACMP Communication Interfaces/Devices
->Add Communication Interfaces/Devices
->Add Pre-defined Communication Interfaces and Devices
-> Communication Interfaces
选择之前建立 的net_ether_01增加2个boot地址:
同样,将其他boot地址加入。
2.4.4.添加心跳网络及接口(二选一)
->diskdb
1. 串口心跳
smitty hacmp-> Extended Configuration
-> Extended Topology Configuration
->Configure HACMP Networks
->Add a Network to the HACMP Cluster
->rs232
添加心跳设备接口:
smitty hacmp-> Extended Configuration
-> Extended Topology Configuration
->Configure HACMP Communication Interfaces/Devices
->Add Communication Interfaces/Devices
->Add Pre-defined Communication Interfaces and Devices
-> Communication Devices
>选择之前建立的net_rs232_01
# Node Device Device Path
host1 tty0 /dev/tty0
host2 tty0 /dev/tty0
2. 磁盘心跳
smitty hacmp->System Management (C-SPOC)
->Storage->Volume Groups
->Manage Concurrent Access Volume Groups for Multi-Node Disk Heartbeat
->Create a new Volume Group and Logical Volume for Multi-Node Disk Heartbeat
选择之前的预先认出的hdisk5这块心跳磁盘。
比之前更简单,一个菜单即同时完成了磁盘心跳VG、LV、网络、设备在2个节点的添加。
至此HACMP的拓扑结构已配置完成。
2.4.5.察看确认拓扑(toplog)结构
smit hacmp->Extended Configuration
->Extended Topology Configuration
->Show HACMP Topology
->Show Cluster Topology
Cluster Name: test_cluster
Cluster Connection Authentication Mode: Standard
Cluster Message Authentication Mode: None
Cluster Message Encryption: None
Use Persistent Labels for Communication: No
NODE host1:
Network net_diskhb_01
Network net_diskhbmulti_01
host1_1 /dev/mndhb_lv_01
Network net_ether_01
host1_l1_boot1 10.2.1.21
host1_l1_boot2 10.2.11.1
Network net_ether_02
host1_l2_boot1 10.2.2.1
host1_l2_boot2 10.2.12.1
Network net_rs232_01
NODE host2:
Network net_diskhb_01
Network net_diskhbmulti_01
host2_2 /dev/mndhb_lv_01
Network net_ether_01
host2_l1_boot2 10.2.11.2
host2_l1_boot1 10.2.1.22
Network net_ether_02
host2_l2_boot1 10.2.2.2
host2_l2_boot2 10.2.12.2
Network net_rs232_01
如心跳为串口心跳则为:
Cluster Name: test_cluster
Cluster Connection Authentication Mode: Standard
Cluster Message Authentication Mode: None
Cluster Message Encryption: None
Use Persistent Labels for Communication: No
NODE host1:
Network net_ether_01
host1_l1_boot1 10.2.1.21
host1_l1_boot2 10.2.11.1
Network net_ether_02
host1_l2_boot1 10.2.2.1
host1_l2_boot2 10.2.12.1
Network net_rs232_01
host1_tty0_01 /dev/tty0
NODE host2:
Network net_ether_01
host2_l1_boot2 10.2.11.2
host2_l1_boot1 10.2.1.22
Network net_ether_02
host2_l2_boot1 10.2.2.2
host2_l2_boot2 10.2.12.2
Network net_rs232_01
host2_tty0_01 /dev/tty0
可以看到已符合规划要求,可继续了
2.5. 创建资源2.5.1.添加高可用资源
(service ip , application server , vg and fs )
1) 添加app server
smitty hacmp ->Extended Configuration
->Extended Resource Configuration
->HACMP Extended Resources Configuration
->Configure HACMP Applications
->Configure HACMP Application Servers
->Add an Application Server
* Server Name [host1_app]
*Start
Script
[/usr/sbin/cluster/app/start_host1]
* Stop Script [/usr/sbin/cluster/app/stop_host1]
Application Monitor Name(s)
同样增加 host2_app
* Server Name [host2_app]
*Start
Script [/usr/sbin/cluster/app/start_host2]
* Stop Script [/usr/sbin/cluster/app/stop_host2]
2) 添加service ip
smity hacmp ->Extended Configuration
->Extended Resource Configuration
->HACMP Extended Resources Configuration
->Configure HACMP Service IP Labels/Addresses
->Add a Service IP Label/Address
->Configurable on Multiple Nodes
选择net_ether_01(10.2.1.0/24 10.2.11.0/24)
* IP Label/Address host1_l1_svc
* Network Name net_ether_01
Alternate HW Address to accompany IP Label/Address []
同样增加其他服务ip地址。
3) 创建资源组
smitty hacmp->Extended Configuration
-> Extended Resource Configuration
->HACMP Extended Resource Group Configuration
-> Add a Resource Group
Add a Resource Group (extended)
Type or select values in entry fields.
Press Enter AFTER making all desired changes. [Entry Fields]
* Resource Group Name [host1_RG]
* Participating Nodes (Default Node Priority) [host1 host2]
Startup Policy Online On Home Node Only
Fallover Policy Fallover To Next Priority Node In The List
Fallback Policy Fallback To Higher Priority Node In The List
同样建立host2_RG,
….
Resource Group Name [host2_RG]
* Participating Nodes (Default Node Priority) [host2 host1]
…
注意,这里如果是主备模式,如host2仅做备机,则为:
Resource Group Name [host2_RG]
* Participating Nodes (Default Node Priority) [host2]
…
4) 配置资源组
smitty hacmp->Extended Configuration
->Extended Resource Configuration
->HACMP Extended Resource Group Configuration
->Change/Show Resources and Attributes for a Resource Group
选择host1_RG
Change/Show All Resources and Attributes for a Resource Group
Type or select values in entry fields.
Press Enter AFTER making all desired changes.
[Entry Fields]
Resource Group Name host1_RG
Participating Nodes (Default Node Priority) host1 host2
Startup Policy Online On Home Node Only
Fallover Policy Fallover To Next Priority Node In The List
Fallback Policy Fallback To Higher Priority Node In The List
Fallback Timer Policy (empty is immediate) []
Service IP Labels/Addresses [host1_l1_svc1 host1_l1_svc2 host1_l2_svc ]
Application Servers [host1_app]
Volume Groups [host1vg]
Use forced varyon of volume groups, if necessary false
同样的方法配置host2_RG
2.5.2.检查和同步HACMP配置
(注意:以上配置均在host1上完成,同步至少2次,先强制同步到host2)
smitty hacmp ->Extended Configuration
->Extended Verification and Synchronization
1)首次强制同步:
HACMP Verification and Synchronization
Type or select values in entry fields.
Press Enter AFTER making all desired changes.
[Entry Fields]
* Verify, Synchronize or Both [Both]
* Automatically correct errors found during [Yes]
verification?
* Force synchronization if verification fails? [Yes]
* Verify changes only? [No]
* Logging [Standard]
2)二次同步:
HACMP Verification and Synchronization
Type or select values in entry fields.
Press Enter AFTER making all desired changes.
[Entry Fields]
* Verify, Synchronize or Both [Both]
* Automatically correct errors found during [Yes]
verification?
* Force synchronization if verification fails? [No]
* Verify changes only? [No]
* Logging [Standard]
注:此处结果为OK才能继续,否则按后续故障章节根据错误信息查找原因处理.
2.6. 最后的其他配置2.6.1. 再次修改/etc/hosts
将其改为svc的地址上,因为HACMP启动后即以此地址对外服务,主机名需要对应。
10.2.2.1 host1_l2_boot1
10.2.1.21 host1_l1_boot1
10.2.200.1 host1_l2_svc host1
10.2.100.1 host1_l1_svc1
10.2.101.1 host1_l1_svc2
10.2.12.1 host1_l2_boot2
10.2.11.1 host1_l1_boot2
10.2.2.2 host2_l2_boot1
10.2.1.22 host2_l1_boot1
10.2.200.2 host2_l2_svc host2
10.2.100.2 host2_l1_svc1
10.2.101.2 host2_l1_svc2
10.2.12.2 host2_l2_boot2
10.2.11.2 host2_l1_boot2
2.6.2.修改syncd daemon的数据刷新频率
该值表示刷新内存数据到硬盘的频率,缺省为60,HACMP安装后一般可改为10,立刻即可生效。
smitty hacmp -> HACMP Extended Configuration
-> Extended Performance Tuning Parameters Configuration
-> Change/Show syncd frequency
修改为10秒
or
运行命令/usr/es/sbin/cluster/utilities/clchsyncd 10亦可
确认:
[host1][root]#ps -ef|grep sync
root 11927616 1 0 16:11:23 pts/0 2:31 /usr/sbin/syncd 10
2.6.3.配置clinfo
注:对于双节点,clstat等监控集群信息软件的基础为clinfoES服务,必须运行在每个Node节点上。
1)修改确认每台机器的/es/sbin/cluster/etc/clhosts为:
127.0.0.1 loopback localhost # loopback (lo0) name/address
10.2.2.1 host1_l2_boot1
10.2.1.21 host1_l1_boot1 host1
10.2.200.1 host1_l2_svc
10.2.100.1 host1_l1_svc1
10.2.101.1 host1_l1_svc2
10.2.12.1 host1_l2_boot2
10.2.11.1 host1_l1_boot2
10.2.2.2 host2_l2_boot1
10.2.1.22 host2_l1_boot1 host2
10.2.200.2 host2_l2_svc
10.2.100.2 host2_l1_svc1
10.2.101.2 host2_l1_svc2
10.2.12.2 host2_l2_boot2
10.2.11.2 host2_l1_boot2
执行拷贝:
rcp /usr/es/sbin/cluster/etc/clhosts host2:/usr/es/sbin/cluster/etc/clhosts
2)将snmp v3转换为snmp v1
/usr/sbin/snmpv3_ssw -1
3) 修改启动clinfoES
chssys -s clinfoES -a "-a"
startsc -s clinfoES
确认:
[host1][root][/]#rsh host1 ls -l /usr/es/sbin/cluster/etc/clhosts
-rw-r--r-- 1 root system 4148 Sep 16 10:27 /usr/es/sbin/cluster/etc/clhosts
[host1][root][/]#rsh host2 ls -l /usr/es/sbin/cluster/etc/clhosts
-rw-r--r-- 1 root system 4148 Sep 16 10:27 /usr/es/sbin/cluster/etc/clhosts
/usr/es/sbin/cluster/clstat运行不报错。
注意:此步骤不能疏漏,必须确保clinfo实施完成后正常运行,否则后续集群状态检查cldump、clstat将均报错,集群状态将无法检查监控。
恭喜!到此为止我们的HACMP已经基本配置完成了。
2.6.4. 启动HACMP:
在所有节点分别启动HACMP服务:
smitty clstart
Type or select values in entry fields.
Press Enter AFTER making all desired changes.
[Entry Fields]
* Start now, on system restart or both now +
Start Cluster Services on these nodes [host1] +
* Manage Resource Groups Automatically +
BROADCAST message at startup? false +
Startup Cluster Information Daemon? true +
Ignore verification errors? false +
Automatically correct errors found during Interactively +
cluster start?
Start Cluster Services
Type or select values in entry fields.
Press Enter AFTER making all desired changes.
[Entry Fields]
* Start now, on system restart or both now +
Start Cluster Services on these nodes [host2] +
* Manage Resource Groups Automatically +
BROADCAST message at startup? false +
Startup Cluster Information Daemon? true +
Ignore verification errors? false +
Automatically correct errors found during Interactively +
cluster start?
2.6.5. 确认HACMP配置完成
使用HACMP的工具clverify,cldump,clstat检查,参见运维篇的日常检查一节。另外从安全角度,记得清理掉 /.rhosts文件。
HACMP首次配置后,这个步骤会和实际应用程序的安装配置工作交织在一起,时间跨度较长,并可能有反复,所以单独列出一章。并利用首次配置没有完成的设计部分,加以举例讲解,实际如设计清楚,可以首次配置即完成。
此过程如果不注意实施细节,会导致两边配置不一致,HACMP在最终配置时需要重新整理VG或同步增加用户等工作。
本章的其他操作和运维篇的变更与实现近乎雷同,只对添加部分介绍。
利用C-SPOC,我们可以实现在任一台节点机上操作共享或并发的LVM组件(VG,lv,fs),系统的clcomd的Demon自动同步到其他机器上。
root 237690 135372 0 Dec 19 - 0:26 /usr/es/sbin/cluster/clcomd -d
2.7.1.增加组和用户利用HACMP的功能,只需在一台机器如host1上操作,会自动同步到另一台如host2。
增加组:
smitty hacmp->System Management (C-SPOC)
-> Security and Users
-> Groups in an HACMP cluster
-> Add a Group to the Cluster
选择host2_RG
Add a Group to the Cluster
Type or select values in entry fields.
Press Enter AFTER making all desired changes.
[Entry Fields]
Select nodes by Resource Group host2_RG
*** No selection means all nodes! ***
* Group NAME [dba]
ADMINISTRATIVE group? false
Group ID [601]
….
同样在host1_RG增加tux组.
增加用户
smitty hacmp->System Management (C-SPOC)
-> Security and Users
->Users in an HACMP cluster
-> Add a User to the Cluster
选择host2_RG
Add a User to the Cluster
Type or select values in entry fields.
Press Enter AFTER making all desired changes.
[TOP] [Entry Fields]
Select nodes by Resource Group host2_RG
*** No selection means all nodes! ***
* User NAME [orarun]
User ID [609]
Primary GROUP [dba]
....
其他根据具体情况可设置
同样在host1_RG增加orarunc,xcom等用户
确认:
[host2][root][/]>lsgroup ALL
[host2][root][/]> lsuser -a id groups ALL
注意:是在host1上执行建组和用户的动作,在host2上确认结果
初始化用户口令
smitty hacmp->System Management (C-SPOC)
-> Security and Users
-> Passwords in an HACMP cluster
-> Change a User's Password in the Cluster
Selection nodes by resource group host2_RG
*** No selection means all nodes! ***
* User NAME [orarun]
User must change password on first login? false
此时需要你输入新口令更改:
COMMAND STATUS
Command: running stdout: no stderr: no
Before command completion, additional instructions may appear below.
orarun's New password: ******
Enter the new password again:******
OK即成功,当然其他用户也需要。
2.7.2.增加lv和文件系统
同样利用HACMP的C-SPOC功能,只需在一台机器操作,会自动同步到另一台,无需考虑VG是否varyon。
增加lv:
smitty HACMP-> System Management (C-SPOC)
-> Storage
-> Logical Volumes
->Add a Logical Volume
选择host2vg host2_RG
host2 hdisk3
Add a Logical Volume
Type or select values in entry fields.
Press Enter AFTER making all desired changes.
[TOP] [Entry Fields]
Resource Group Name host2_RG
VOLUME GROUP name host2vg
Node List host1,host2
Reference node host2
* Number of LOGICAL PARTITIONS [80] #
PHYSICAL VOLUME names hdisk3
Logical volume NAME [oradatalv]
Logical volume TYPE [jfs2] +
POSITION on physical volume outer_middle +
RANGE of physical volumes minimum +
同样建立host1_RG的其他lv。
建立文件系统:
smitty hacmp-> System Management (C-SPOC)
-> Storage
-> File Systems
-> Add a File System
选择 host2vg host2_RG
Enhanced Journaled File System
oradatalv host1,host2
….
同样建立其他文件系统,建立好后,这些文件系统自动mount。
确认:
[host2][root][/]#df -g
....
/dev/oradatalv 10.00 10.00 1% 4 1% /oradata
修改文件系统的目录权限,保证两边一致,。
[host2][root][/]>chown orarun:dba /ora11run
[host2][root][/]>umount /ora11run
[host2][root][/]>chown orarun:dba /ora11run
[host1][root][/]>chown orarun:dba /ora11run
同样其他文件系统也要如此操作。
注意:修改3遍的原因为有些应用对mount前文件系统的目录也有权限要求,此外两边权限不一致也会导致切换时脚本不能正常访问文件系统,详见日常运维篇。
确认:
[host2][root][/]>df -g
[host2][root][/]>ls -l /oradata
[host1][root][/]>df -g
等
2.7.3.安装和配置应用
这里包括安装配置host2上的数据库和host1上的tuxedo、mes、通信软件,由于和HACMP本身关系不大,所以不再描述。
2.8. 最终配置(带应用的HACMP配置)这一步一般在应用程序已经稳定,不做大的变动时进行。大都是在系统快上线前的一段时间进行,伴随最终设置的完成,应该跟随一个完整测试。
这一步也可以理解为“带应用的HACMP配置”,所以主要工作是确认在HACMP的切换等行为中,应用脚本的正确性和健壮性。
2.8.1.起停脚本已经编写完备并本机测试自行编写脚本,也可参见脚本篇编写,并通过启停测试。
2.8.2. 同步脚本和用户的.profile等环境文件
可先在其中一台如host1测完所有脚本,然后统一同步到另一台。
[host1][root][/]>rcp -rp /usr/sbin/cluster/app host2:/usr/sbin/cluster/
[host1][root][/home]>tar -cvf host2_user.tar ora11run
[host1][root][/home]>rcp host2_user.tar host2:/home
[host1][root][/home]>tar -xvf host2_user.tar
[host1][root][/home] >tar -cvf host1_user.tar ora11runc tuxrun bsx1 xcom
[host1][root][/home]>rcp host1_user.tar host2:/home
[host2][root][/home]>tar -xvf host1_user.tar
如采用了本文的脚本篇的编制方式,也不要忘了同步
[host2][root][/home/scripts]>rcp -rp comm host1:/home
[host1][root][/home/scripts]>rcp -rp host2 host1:/home/scripts
[host1][root][/home/scripts]>rcp -rp host1:/home/scripts/host1 .
2.8.3.确认检查和处理
这一步是确认经过一段时间后,HACMP是否需要修正和同步,参考运维篇的日常检查及处理。
2.8.4.测试:
至此,我们完成了整个HACMP的上线前的集成实施工作,具备了系统上线的条件。
2. 第三部分--测试篇虽然HACMP提供了自动化测试工具test tool,使用起来也较为简单。但个人认为由于HACMP的完整测试是一个比较复杂的事情,工具虽然出来了蛮久的,但似乎感觉还是不能非常让人放心,何况也无法模拟交换机等故障,所以只能提供协助,不能完全依赖,结果仅供参考。
2.1. 测试方法说明:1. ping测试:从client同时发起,每次1024个字节,延续10分钟。
2. ping长测试:每次1024个字节,延续24小时。
3. 应用测试:利用自动化测试工具如loadrunner持续从 client连接应用服务使用查询。
4. 应用长测试:48小时内,进行应用测试使用。
5. telnet测试:telnet连接后根据情况确认。
2.2. 标准测试这个测试为必须完成的测试,网络部分每个网段都要做一次,时间节点一般为安装配置中的初始配置阶段,最终配置阶段以及运维定修阶段。
2.2.1.标准测试表
注意:每步动作后,需要采用clstat确保HACMP已处于STABLE稳定状态再做下一步动作,尤其是恢复动作(对于4,10 实际为3个小步骤),最好间隔120-300s,否则HACMP由于状态不稳定来不及做出判断,出现异常。
|
序号 |
测试步骤 |
系统结果 |
应用结果 |
|
1 |
拔掉host1的服务网线 |
地址漂移到另一个网卡 |
中断30s左右可继续使用 |
|
2 |
拔掉host1的剩下一根的网线 |
发生切换 |
中断5分钟左右可继续使用 |
|
3 |
拔掉host2的服务网线 |
所有服务地址漂到另一网卡 |
中断30s左右可继续使用 |
|
4 |
恢复所有网线
|
地址join,clstat可看到均up |
无影响 |
|
5 |
在host2上执行ha1t -q |
host2机宕机,切换到host1机 |
中断5分钟左右可继续使用 |
|
|
|
|
|
|
6 |
起动host2机器,在host2上手工执行 smit clstart回原集群 |
host1上的属于host2的相关资源及服务切换回host2,集群回到设计状态 |
中断5分钟左右可继续使用 |
|
|
|
|
|
|
7 |
拔掉host2的服务网线 |
地址漂另一个网卡 |
中断30s左右可继续使用 |
|
8 |
拔掉host2的剩下一根的网线 |
发生切换 |
中断5分钟左右可继续使用 |
|
9 |
拔掉host1的服务网线 |
所有服务地址漂到另一网卡 |
中断30s左右可继续使用 |
|
10 |
恢复所有网线 |
地址join,clstat可看到 均up |
无影响 |
|
11 |
在host1上执行halt -q |
host1机宕机,切换到host2机 |
中断5分钟左右可继续使用 |
|
起动host1机器,在host1上手工执行 smit clstart回原集群 |
host2上的属于host1的相关资源及服务切换回host1,集群回到设计状态 |
中断5分钟左右可继续使用 |
以下为日志/var/hacmp/log/hacmp.out的部分分析,供大家实际测试参考:
步骤1:拔掉host1的服务网线
Sep 16 14:53:10 EVENT START: swap_adapter host1 net_ether_02 10.2.12.1 10.2.200.1
Sep 16 14:53:12 EVENT START: swap_aconn_protocols en3 en1
Sep 16 14:53:12 EVENT COMPLETED: swap_aconn_protocols en3 en1 0
Sep 16 14:53:12 EVENT COMPLETED: swap_adapter host1 net_ether_02 10.2.12.1 10.2.200.1 0
Sep 16 14:53:12 EVENT START: swap_adapter_complete host1 net_ether_02 10.2.12.1 10.2.200.1
Sep 16 14:53:13 EVENT COMPLETED: swap_adapter_complete host1 net_ether_02 10.2.12.1 10.2.200.1 0
步骤2:拔掉host1的剩下一根的网线
Sep 16 14:53:14 EVENT START: fail_interface host1 10.2.2.1
Sep 16 14:53:14 EVENT COMPLETED: fail_interface host1 10.2.2.1 0
Sep 16 14:53:55 EVENT START: network_down host1 net_ether_02
Sep 16 14:53:56 EVENT COMPLETED: network_down host1 net_ether_02 0
Sep 16 14:53:56 EVENT START: network_down_complete host1 net_ether_02
Sep 16 14:53:56 EVENT COMPLETED: network_down_complete host1 net_ether_02 0
Sep 16 14:54:03 EVENT START: rg_move_release host1 1
Sep 16 14:54:03 EVENT START: rg_move host1 1 RELEASE
Sep 16 14:54:03 EVENT START: node_down_local
Sep 16 14:54:03 EVENT START: stop_server host2_app host1_app
Sep 16 14:54:04 EVENT COMPLETED: stop_server host2_app host1_app 0
Sep 16 14:54:04 EVENT START: release_vg_fs ALL host1vg
Sep 16 14:54:06 EVENT COMPLETED: release_vg_fs ALL host1vg 0
Sep 16 14:54:06 EVENT START: release_service_addr host1_l1_svc1 host1_l1_svc2 host1_l2_svc
Sep 16 14:54:11 EVENT COMPLETED: release_service_addr host1_l1_svc1 host1_l1_svc2 host1_l2_svc 0
Sep 16 14:54:11 EVENT COMPLETED: node_down_local 0
Sep 16 14:54:11 EVENT COMPLETED: rg_move host1 1 RELEASE 0
Sep 16 14:54:11 EVENT COMPLETED: rg_move_release host1 1 0
Sep 16 14:54:13 EVENT START: rg_move_fence host1 1
Sep 16 14:54:14 EVENT COMPLETED: rg_move_fence host1 1 0
Sep 16 14:54:14 EVENT START: rg_move_acquire host1 1
Sep 16 14:54:14 EVENT START: rg_move host1 1 ACQUIRE
Sep 16 14:54:14 EVENT COMPLETED: rg_move host1 1 ACQUIRE 0
Sep 16 14:54:14 EVENT COMPLETED: rg_move_acquire host1 1 0
Sep 16 14:54:24 EVENT START: rg_move_complete host1 1
Sep 16 14:54:25 EVENT START: node_up_remote_complete host1
Sep 16 14:54:25 EVENT COMPLETED: node_up_remote_complete host1 0
Sep 16 14:54:25 EVENT COMPLETED: rg_move_complete host1 1 0
步骤4:恢复所有网线
Sep 16 14:55:49 EVENT START: network_up host1 net_ether_02
Sep 16 14:55:49 EVENT COMPLETED: network_up host1 net_ether_02 0
Sep 16 14:55:50 EVENT START: network_up_complete host1 net_ether_02
Sep 16 14:55:50 EVENT COMPLETED: network_up_complete host1 net_ether_02 0
Sep 16 14:56:00 EVENT START: join_interface host1 10.2.12.1
Sep 16 14:56:00 EVENT COMPLETED: join_interface host1 10.2.12.1 0
步骤5:在host2上执行ha1t -q
Sep 16 14:58:56 EVENT START: node_down host2
Sep 16 14:58:57 EVENT START: acquire_service_addr
Sep 16 14:58:58 EVENT START: acquire_aconn_service en0 net_ether_01
Sep 16 14:58:59 EVENT COMPLETED: acquire_aconn_service en0 net_ether_01 0
Sep 16 14:59:00 EVENT START: acquire_aconn_service en2 net_ether_01
Sep 16 14:59:00 EVENT COMPLETED: acquire_aconn_service en2 net_ether_01 0
Sep 16 14:59:01 EVENT START: acquire_aconn_service en1 net_ether_02
Sep 16 14:59:01 EVENT COMPLETED: acquire_aconn_service en1 net_ether_02 0
Sep 16 14:59:01 EVENT COMPLETED: acquire_service_addr 0
Sep 16 14:59:02 EVENT START: acquire_takeover_addr
Sep 16 14:59:05 EVENT COMPLETED: acquire_takeover_addr 0
Sep 16 14:59:11 EVENT COMPLETED: node_down host2 0
Sep 16 14:59:11 EVENT START: node_down_complete host2
Sep 16 14:59:12 EVENT START: start_server host1_app host2_app
Sep 16 14:59:12 EVENT START: start_server host2_app
Sep 16 14:59:12 EVENT COMPLETED: start_server host1_app host2_app 0
Sep 16 14:59:12 EVENT COMPLETED: start_server host2_app 0
Sep 16 14:59:13 EVENT COMPLETED: node_down_complete host2 0
步骤6:回原
Sep 16 15:10:25 EVENT START: node_up host2
Sep 16 15:10:27 EVENT START: acquire_service_addr
Sep 16 15:10:28 EVENT START: acquire_aconn_service en0 net_ether_01
Sep 16 15:10:28 EVENT COMPLETED: acquire_aconn_service en0 net_ether_01 0
Sep 16 15:10:29 EVENT START: acquire_aconn_service en2 net_ether_01
Sep 16 15:10:29 EVENT COMPLETED: acquire_aconn_service en2 net_ether_01 0
Sep 16 15:10:31 EVENT START: acquire_aconn_service en1 net_ether_02
Sep 16 15:10:31 EVENT COMPLETED: acquire_aconn_service en1 net_ether_02 0
Sep 16 15:10:31 EVENT COMPLETED: acquire_service_addr 0
Sep 16 15:10:36 EVENT COMPLETED: node_up host2 0
Sep 16 15:10:36 EVENT START: node_up_complete host2
Sep 16 15:10:36 EVENT START: start_server host2_app
Sep 16 15:10:37 EVENT COMPLETED: start_server host2_app 0
Sep 16 15:10:37 EVENT COMPLETED: node_up_complete host2 0
Sep 16 15:10:41 EVENT START: network_up host2 net_diskhbmulti_01
Sep 16 15:10:42 EVENT COMPLETED: network_up host2 net_diskhbmulti_01 0
Sep 16 15:10:42 EVENT START: network_up_complete host2 net_diskhbmulti_01
Sep 16 15:10:42 EVENT COMPLETED: network_up_complete host2 net_diskhbmulti_01 0
步骤7:拔掉host2的服务网线
Sep 16 15:20:36 EVENT START: swap_adapter host2 net_ether_02 10.2.12.2 10.2.200.2
Sep 16 15:20:38 EVENT START: swap_aconn_protocols en3 en1
Sep 16 15:20:38 EVENT COMPLETED: swap_aconn_protocols en3 en1 0
Sep 16 15:20:38 EVENT COMPLETED: swap_adapter host2 net_ether_02 10.2.12.2 10.2.200.2 0
Sep 16 15:20:39 EVENT START: swap_adapter_complete host2 net_ether_02 10.2.12.2 10.2.200.2
Sep 16 15:20:39 EVENT COMPLETED: swap_adapter_complete host2 net_ether_02 10.2.12.2 10.2.200.2 0
步骤8:拔掉host2的剩下一根的网线
Sep 16 15:20:40 EVENT START: fail_interface host2 10.2.2.2
Sep 16 15:20:40 EVENT COMPLETED: fail_interface host2 10.2.2.2 0
Sep 16 15:21:40 EVENT START: network_down host2 net_ether_02
Sep 16 15:21:40 EVENT COMPLETED: network_down host2 net_ether_02 0
Sep 16 15:21:40 EVENT START: network_down_complete host2 net_ether_02
Sep 16 15:21:41 EVENT COMPLETED: network_down_complete host2 net_ether_02 0
Sep 16 15:21:47 EVENT START: rg_move_release host2 2
Sep 16 15:21:47 EVENT START: rg_move host2 2 RELEASE
Sep 16 15:21:48 EVENT START: node_down_local
Sep 16 15:21:48 EVENT START: stop_server host2_app
Sep 16 15:21:48 EVENT COMPLETED: stop_server host2_app 0
Sep 16 15:21:48 EVENT START: release_vg_fs ALL host2vg
Sep 16 15:21:50 EVENT COMPLETED: release_vg_fs ALL host2vg 0
Sep 16 15:21:50 EVENT START: release_service_addr host2_l1_svc1 host2_l1_svc2 host2_l2_svc
Sep 16 15:21:55 EVENT COMPLETED: release_service_addr host2_l1_svc1 host2_l1_svc2 host2_l2_svc 0
Sep 16 15:21:55 EVENT COMPLETED: node_down_local 0
Sep 16 15:21:55 EVENT COMPLETED: rg_move host2 2 RELEASE 0
Sep 16 15:21:55 EVENT COMPLETED: rg_move_release host2 2 0
Sep 16 15:21:57 EVENT START: rg_move_fence host2 2
Sep 16 15:21:58 EVENT COMPLETED: rg_move_fence host2 2 0
Sep 16 15:21:58 EVENT START: rg_move_acquire host2 2
Sep 16 15:21:58 EVENT START: rg_move host2 2 ACQUIRE
Sep 16 15:21:58 EVENT COMPLETED: rg_move host2 2 ACQUIRE 0
Sep 16 15:21:58 EVENT COMPLETED: rg_move_acquire host2 2 0
Sep 16 15:22:08 EVENT START: rg_move_complete host2 2
Sep 16 15:22:08 EVENT START: node_up_remote_complete host2
Sep 16 15:22:09 EVENT COMPLETED: node_up_remote_complete host2 0
Sep 16 15:22:09 EVENT COMPLETED: rg_move_complete host2 2 0
步骤9:拔掉host1的服务网线
Sep 16 15:43:42 EVENT START: swap_adapter host1 net_ether_02 10.2.2.1 10.2.200.2
Sep 16 15:43:43 EVENT COMPLETED: swap_adapter host1 net_ether_02 10.2.2.1 10.2.200.2 0
Sep 16 15:43:45 EVENT START: swap_adapter_complete host1 net_ether_02 10.2.2.1 10.2.200.2
Sep 16 15:43:45 EVENT COMPLETED: swap_adapter_complete host1 net_ether_02 10.2.2.1 10.2.200.2 0
Sep 16 15:43:47 EVENT START: fail_interface host1 10.2.12.1
Sep 16 15:43:47 EVENT COMPLETED: fail_interface host1 10.2.12.1 0
步骤10:恢复所有网线
Sep 16 15:45:07 EVENT START: network_up host2 net_ether_02
Sep 16 15:45:08 EVENT COMPLETED: network_up host2 net_ether_02 0
Sep 16 15:45:08 EVENT START: network_up_complete host2 net_ether_02
Sep 16 15:45:08 EVENT COMPLETED: network_up_complete host2 net_ether_02 0
Sep 16 15:45:43 EVENT START: join_interface host2 10.2.12.2
Sep 16 15:45:43 EVENT COMPLETED: join_interface host2 10.2.12.2 0
Sep 16 15:47:05 EVENT START: join_interface host1 10.2.12.1
Sep 16 15:47:05 EVENT COMPLETED: join_interface host1 10.2.12.1 0
步骤11:在host1上执行halt -q
Sep 16 15:48:48 EVENT START: node_down host1
Sep 16 15:48:49 EVENT START: acquire_service_addr
Sep 16 15:48:50 EVENT START: acquire_aconn_service en0 net_ether_01
Sep 16 15:48:50 EVENT COMPLETED: acquire_aconn_service en0 net_ether_01 0
Sep 16 15:48:51 EVENT START: acquire_aconn_service en2 net_ether_01
Sep 16 15:48:51 EVENT COMPLETED: acquire_aconn_service en2 net_ether_01 0
Sep 16 15:48:53 EVENT START: acquire_aconn_service en1 net_ether_02
Sep 16 15:48:53 EVENT COMPLETED: acquire_aconn_service en1 net_ether_02 0
Sep 16 15:48:53 EVENT COMPLETED: acquire_service_addr 0
Sep 16 15:48:53 EVENT START: acquire_takeover_addr
Sep 16 15:48:57 EVENT COMPLETED: acquire_takeover_addr 0
Sep 16 15:49:02 EVENT COMPLETED: node_down host1 0
Sep 16 15:49:02 EVENT START: node_down_complete host1
Sep 16 15:49:03 EVENT START: start_server host1_app host2_app
Sep 16 15:49:03 EVENT START: start_server host2_app
Sep 16 15:49:03 EVENT COMPLETED: start_server host1_app host2_app 0
Sep 16 15:49:03 EVENT COMPLETED: start_server host2_app 0
Sep 16 15:49:04 EVENT COMPLETED: node_down_complete host1 0
2.3. 完全测试
完全测试在有充分测试时间和测试条件(如交换机可参与测试)完整加以测试,时间节点一般为系统上线前一周。
注:考虑到下表的通用性,有2种情况没有细化,需要注意。
1. 同一网络有2个服务IP地址,考虑到负载均衡,将自动分别落在boot1、boot2上,这样不论那个网卡有问题,都会发生地址漂移。
2. 应用中断没有加入应用的重新连接时间,如oracleDB发生漂移,实际tuxedo需要重新启动才可继续连接,这个需要起停脚本来实现。
此外,由于实际环境也许有所不同甚至更为复杂,此表仅供大家实际参考,但大体部分展现出来,主要提醒大家不要遗漏。
2.3.1.完全测试表
|
序号 |
测试场景 |
系统结果 |
应用结果 |
参考时长 |
|
|
功能测试 |
|
|
|
|
1 |
host2起HA |
host2服务IP地址生效,vg、文件系统生效 |
host2 app(db)启动OK |
120s |
|
2 |
host2停HA |
host2服务IP地址、vg释放干净 |
host2 app 停止 |
15s |
|
3 |
host1起HA |
host1服务IP地址生效,vg、文件系统生效 |
host1 app启动OK |
120s |
|
4 |
host1停HA |
host1网卡、vg释放干净 |
host2 app 停止 |
15s |
|
5 |
host2 takeover切换host1 |
host2服务地址切换到host1的boot2和vg等 |
host2 app 短暂中断 |
30s |
|
host2 clstart |
回原 |
host2 app短暂中断 |
120s |
|
|
6 |
host1 takeover到 host2 |
host1服务地址切换到host2的boot2和vg等切换到host2 |
host1 app 短暂中断
|
30s
|
|
host1 clstart |
回原 |
host1 app短暂中断 |
120s |
|
|
|
网卡异常测试 |
|
|
|
|
1 |
host2断boot1网线测试 |
host2的服务ip从boot1漂移至boot2 |
host2 app 短暂中断 |
30s |
|
host2恢复boot1网线测试 |
host2 boot1 join |
无影响 |
40s |
|
|
2 |
host2断boot2网线测试 |
host2的服务ip从boot1漂移至boot2 |
host2 app 短暂中断 |
30s |
|
host2恢复boot2网线测试 |
host2 boot1 join |
无影响 |
40s |
|
|
3 |
host2断boot1、boot2网线测试 |
host2服务地址切换到host1的boot2上,vg等切换到host1 |
host2 app短暂中断 |
210s
|
|
host1再断boot2网线, |
host2的服务ip漂移到host1的boot1 |
host2 app短暂中断 |
30s |
|
|
host2恢复boot1、boot2网线测试 |
host2 boot1,boot 2join |
无影响 |
30s |
|
|
host2 clstart |
回原 |
host2 app短暂中断 |
120s |
|
|
4 |
host1断boot1、boot2网线测试 |
host1服务地址切换到host2的boot2上,vg等切换到host2 |
host1 app短暂中断 |
210s
|
|
host1再断boot2网线, |
host1的服务ip漂移到host2的boot1 |
host1 app短暂中断 |
30s |
|
|
host1恢复boot1、boot2网线测试 |
host1 boot1,boot 2join |
无影响 |
30s |
|
|
host2 clstart |
回原 |
host2 app短暂中断 |
120s |
|
|
5 |
host2 force clstop |
cluster服务停止,ip、vg资源无反应 |
无影响 |
20s |
|
host2 clstart |
回原 |
无影响 |
20s |
|
|
6 |
host1 force clstop |
cluster服务停止,ip、vg资源无反应 |
无影响 |
20s |
|
host1 clstart |
回原 |
无影响 |
20s |
|
|
7 |
host2,host1 boot2 网线同时断30mins |
boot2 failed |
无影响 |
20s |
|
host2,host1 boot2 网线恢复 |
boot2 均join |
无影响 |
20s |
|
|
8 |
host2,host1 boot1 网线同时断30mins |
服务IP地址均漂移到boot2上。 |
host1,host2 app短暂中断 |
30s |
|
host2,host1 boot1 网线恢复 |
boot1 均join |
无影响 |
20s |
|
|
|
主机宕机测试 |
|
|
|
|
1 |
host2 突然宕机halt -q |
host2服务地址切换到host1的boot2和vg等 |
host2 app 短暂中断 |
30s |
|
host2 clstart |
回原 |
host2 app短暂中断 |
120s |
|
|
2 |
host1 突然宕机halt -q |
host1服务地址切换到host2的boot2和vg等切换到host2 |
host1 app 短暂中断
|
30s
|
|
host1 clstart |
回原 |
host1 app短暂中断 |
120s |
|
|
|
交换机异常测试 |
|
|
|
|
1 |
SwitchA断电 |
服务IP地址均漂移到boot2上 |
host1、host2 app短暂中断 |
50s |
|
SwitchA恢复 |
boot1 均join |
无影响 |
40s |
|
|
SwitchB断电 |
服务IP地址均漂移回boot1上 |
host1、host2 app短暂中断 |
50s |
|
|
SwitchB恢复 |
boot2 均join |
无影响 |
40s |
|
|
2 |
SwitchB断电 |
boot2 failed |
无影响 |
50s |
|
SwitchB恢复 |
boot2 均join |
无影响 |
40s |
|
|
SwitchA断电 |
服务IP地址均漂移到boot2上。 |
host1、host2 app短暂中断 |
50s |
|
|
SwitchA恢复 |
boot1 均join |
无影响 |
40s |
|
|
3 |
SwitchA,B同时断电10mins |
network报down,其他一切不动。 |
host1、host2 app中断 |
10min |
|
SwitchA,B恢复 |
boot1,boot2 join |
服务自动恢复 |
50s |
|
|
4 |
SwitchA断电
|
服务IP地址均漂移到boot2上 |
host1、host2 app短暂中断 |
50s |
|
30s后B也断电 |
不动 |
host1、host2 app中断 |
50s |
|
|
SwitchA,B恢复 |
boot1 均join |
自动恢复 |
40s |
|
|
5 |
SwitchB断电
|
boot2 failed |
无影响 |
50s |
|
30s后A也断电 |
network报down,其他一切不动。 |
host1、host2 app中断 |
50s |
|
|
SwitchA,B恢复 |
boot1 均join |
自动恢复 |
40s |
|
|
6 |
SwitchA异常(对接网线触发广播风暴) |
机器本身正常,但网络不通
|
host1、host2 app中断 |
20s |
|
SwitchA恢复 |
恢复后一切正常 |
自动恢复 |
|
|
|
7 |
SwitchB异常(对接网线触广播风暴) |
机器本身正常,但网络不通 恢复后一切正常 |
host1、host2 app中断 |
20s |
|
SwitchB恢复 |
|
自动恢复 |
|
|
|
8 |
SwitchA,B同时异常(对接网线触广播风暴) |
机器本身正常,但网络丢包严重,
|
host1、host2 app中断 |
10s |
|
|
SwitchA,B恢复 |
恢复后一切正常 |
自动恢复 |
20s |
|
|
稳定性测试 |
|
|
|
|
1 |
host2, host1各起HA |
|
48小时以上正常服务 |
|
|
2 |
host2 takeover切换host1 |
|
48小时以上正常服务 |
|
|
3 |
host1 takeover到 host2 |
|
48小时以上正常服务 |
|
2.4. 运维切换测试:
运维切换测试是为了在运维过程中,为保证高可靠性加以实施。建议每年实施一次。因为这样的测试实际是一种演练,能够及时发现各方面的问题,为故障期间切换成功提供有效保证。
一直以来,听过不少用户和同仁抱怨,说平时测试完美,实际关键时刻却不能切换,原因其实除了运维篇没做到位之外,还有测试不够充分的原因。 因此本人目前强烈推荐有条件的环境一定要定期进行运维切换测试。
之前由于成本的原因,备机配置一般比主机低,或者大量用于开发测试,很难实施这样的测试。但随着Power机器能力越来越强,一台机器只装一个AIX系统的越来越少,也就使得互备LPAR的资源可以在HA生效是多个LAPR之间直接实时调整资源,使得这样的互换测试成为了可能。
2.4.1.运维切换测试表
|
场景 |
|
建议时长 |
切换方式 |
|
主备(run->dev) |
主机和备机互换 |
>10天 |
备机开发测试停用或临时修改HA配置 |
|
主分区切、备用分区互换 |
>30天 |
备用分区资源增加、主分区资源减少。开发测试停用或临时修改HA配置 |
|
|
互备(app <->db,app<->app,db<->db) |
互换 |
>30天 |
手工互相交叉启动资源组 |
主机切换到备机:
有2种方式:
Ø 可用takeover(move Resource Groups )方式,但由于负荷和防止误操作的原因,备机的开发测试环境一般需要停用。
Ø 也可通过修改HA的配置,将备机资源组的节点数增加运行节点。这样可以在切换测试期间继续使用开发测试环境。但这样不光要对HA有所改动。还要预先配置时就要保证备机开发测试环境也不是放在本地盘上,需要放在共享vg里,此外还要同步开发测试的环境到运行机。建议最好在设计时就有这样的考虑。
手工互相切换:
停掉资源组:
smitty hacmp->System Management (C-SPOC)
-> Resource Group and Applications
->Bring a Resource Group Offline 选择 host2_RG,host2
Bring a Resource Group Offline
Type or select values in entry fields.
Press Enter AFTER making all desired changes.
[Entry Fields]
Resource Group to Bring Offline host2_RG
Node On Which to Bring Resource Group Offline host2
Persist Across Cluster Reboot? false
同样停掉host1_RG
互换资源组:
smitty HACMP->System Management (C-SPOC)
-> Resource Group and Applications
->Bring a Resource Group Online 选择host2_RG,host1
Resource Group to Bring Online host2_RG
Node on Which to Bring Resource Group Online host1
Persist Across Cluster Reboot回答No。
即在host1上启动host2的资源组,同样方法在host2上启动host1资源组。这样2台机器就实现了互换。
注:由于互切需要人工干预,回原也要人工干预,所以切换期间需要密切监控运行状况,如方便出现有异常时,能立刻人工处理。
互换crontab及相关后台脚本:
由于备份作业等crontab里的后台作业会有所不同,所以需要进行互换,按我们的做法(参见脚本篇的同步HA的脚本)只需拷贝相应crontab即可。
[host1][root][/]>cp -rp /home/scripts/host2/crontab_host2 /var/spool/cron/crontabs/root
修正文件属性:
[host1][root][/]>chown root:cron /var/spool/cron/crontabs/root
[host1][root][/]>chmod 600 /var/spool/cron/crontabs/root
重起crontab:
[host1][root][/]> ps -ef|grep cron
root 278688 1 0 Dec 19 - 0:02 /usr/sbin/cron
[host1][root][/]>kill -9 278688
如果不采用我们脚本的做法,除需要拷贝对方的crontab外,还要记得同步相应脚本。
互换备份策略:
由于备份方式不同,可能所作的调整也不一样,需要具体系统具体对待。实验环境中的备份采用后台作业方式,无须进一步处理。实际环境中可能采用备份软件,由于主机互换了,备份策略是否有效需要确认,如无效,需要做相应修正。
第四部分--维护篇作为高可用性的保证,通过了配置和测试之后,系统成功上线了,但不要忘记,HACMP也需要精心维护才能在最关键的时刻发生作用,否则不光是多余的摆设,维护人员会由于“既然已经安装好HACMP了,关键时刻自然会发生作用”的想法反而高枕无忧,麻痹大意。
2.1. HACMP切换问题及处理我们简单统计了以往遇到的切换不成功或误切换的场景,编制了测试成功切换却失败的原因及对策,如下表:
2.1.1.HACMP切换问题表|
故障现象 |
原因 |
根本原因 |
对策 |
|
无法切换1 |
测试一段时间后两边配置不一致、不同步 |
没通过HACMP的功能(含C-SPOC)进行用户、文件系统等系统变更。 |
制定和遵守规范,定期检查,定修及时处理
|
|
无法切换2 |
应用停不下来,导致超时,文件系统不能umount |
停止脚本考虑不周全 |
规范化增加kill_vg_user脚本 |
|
切换成功但应用不正常1 |
应用启动异常 |
应用有变动,停止脚本异常停止或启动脚本不正确 |
规范化和及时更新起停脚本
|
|
切换成功但应用不正常2 |
备机配置不符合运行要求 |
各类系统和软件参数不合适 |
制定检查规范初稿,通过运维切换测试检查确认。 |
|
切换成功但通信不正常1 |
网络路由不通
|
网络配置原因 |
修正测试路由,通过运维切换测试检查确认。 |
|
切换成功但通信不正常2 |
通信软件配置问题 |
由于一台主机同时漂移同一网段的2个服务地址,通信电文从另一个IP地址通信,导致错误 |
修正配置,绑定指定服务ip。 |
|
误切换 |
DMS问题 |
系统负荷持续过高 |
注:请记住,对于客户来说,不管什么原因,“应用中断超过了5-10分钟,就是HACMP切换不成功”,也意味着前面所有的工作都白费了,所以维护工作的重要性也是不言而谕的。
2.1.2.强制方式停掉HACMP:HACMP的停止分为3种,
Bring Resource Groups Offline (正常停止)
Move Resource Groups (手工切换)
Unmanage Resource Groups (强制停掉HACMP,而不停资源组)
下面的维护工作,很多时候需要强制停掉HACMP来进行,此时资源组不会释放,这样做的好处是,由于IP地址、文件系统等等没有任何影响,只是停掉HACMP本身,所以应用服务可以继续提供,实现了在线检查和变更HACMP的目的。
[host1][root][/]>smitty clstop
Stop Cluster Services
Type or select values in entry fields.
Press Enter AFTER making all desired changes.
* Stop now, on system restart or both now
Stop Cluster Services on these nodes [host1]
BROADCAST cluster shutdown? false
* Select an Action on Resource Groups Unmanage Resource Group
记得一般所有节点都要进行这样操作。
用cldump可以看到以下结果:
......
luster Name: test_cluster
Resource Group Name: rg_diskhbmulti_01
Startup Policy: Online On All Available Nodes
Fallover Policy: Bring Offline (On Error Node Only)
Fallback Policy: Never Fallback
Site Policy: ignore
Node Group State
---------------------------- ---------------
host1 UNMANAGED
host2 UNMANAGED
Resource Group Name: host1_RG
Startup Policy: Online On Home Node Only
Fallover Policy: Fallover To Next Priority Node In The List
Fallback Policy: Fallback To Higher Priority Node In The List
Site Policy: ignore
Node Group State
---------------------------- ---------------
host1 UNMANAGED
host2 UNMANAGED
Resource Group Name: host2_RG
Startup Policy: Online On Home Node Only
Fallover Policy: Fallover To Next Priority Node In The List
Fallback Policy: Fallback To Higher Priority Node In The List
Site Policy: ignore
Node Group State
---------------------------- ---------------
host2 UNMANAGED
host1 UNMANAGED
2.1.3.强制停掉后的HACMP启动:
在修改HACMP的配置后,大多数情况下需要重新申请资源启动,这样才能使HACMP的配置重新生效。
[host1][root][/]>smitty clstart
请注意:为保险,Startup Cluster Information Daemon?选择 true。
为了更好的维护好HACMP,平时的检查和处理是必不可少的,下面提供的检查和处理方法除非特别说明,均是不用停机、停止应用即可进行,不影响用户使用。不过具体实施前需要仔细检查状态,再予以实施。
当然,最有说服力的检查和验证是通过运维切换测试,参见测试篇。
2.2.1.clverify检查
这个检查可以对包括LVM的绝大多数HACMP的配置同步状态,是HACMP检查是否同步的主要方式。
smitty clverify ->Verify HACMP Configuration
回车即可
经过检查,结果应是OK。如果发现不一致,需要区别对待。对于非LVM的报错,大多数情况下不用停止应用,可以用以下步骤解决:
1. 先利用强制方式停止HACMP服务。
同样停止host2的HACMP服务。
2. 就检查出的问题进行修正和同步:
smitty hacmp -> Extended Configuration
-> Extended Verification and Synchronization
这时由于已停止HACMP服务,可以包括自动修正和强制同步。
对于LVM的报错,一般是由于未使用HACMP的C-SPOC功能,单边修改文件系统、lv、VG造成的,会造成VG的timestamp不一致。这种情况即使手工在另一边修正(通常由于应用在使用,也不能这样做),选取自动修正的同步,也仍然会报failed。此时只能停掉应用,按首次整理中的整理VG一节解决。
2.2.2.进程检查:
1) 查看服务及进程,至少有以下三个:
[host1][root][/]#lssrc -a|grep ES
clcomdES clcomdES 10027064 active
clstrmgrES cluster 9109532 active
clinfoES cluster 5767310 active
2) /var目录存放hacmp的相关log,还有剩余空间。
2.2.3.cldump检查:
实际HACMP菜单中也可以调用cldump,效果相同。
cldump的监测为将当前HACMP的状态快照,确认显示为UP,STABLE,否则根据实际情况进行分析处理。
[host1][root][/]>/usr/sbin/cluster/utilities/cldump
Obtaining information via SNMP from Node: host1...
_____________________________________________________________________________
Cluster Name: test_cluster
Cluster State: UP
Cluster Substate: STABLE
_____________________________________________________________________________
Node Name: host1 State: UP
Network Name: net_diskhbmulti_01 State: UP
Address: Label: host1_1 State: UP
Network Name: net_ether_01 State: UP
Address: 10.2.100.1 Label: host1_l1_svc1 State: UP
Address: 10.2.101.1 Label: host1_l1_svc2 State: UP
Address: 10.2.11.1 Label: host1_l1_boot2 State: UP
Address: 10.2.1.21 Label: host1_l1_boot1 State: UP
Network Name: net_ether_02 State: UP
Address: 10.2.12.1 Label: host1_l2_boot2 State: UP
Address: 10.2.2.1 Label: host1_l2_boot1 State: UP
Address: 10.2.200.1 Label: host1_l2_svc State: UP
Node Name: host2 State: UP
Network Name: net_diskhbmulti_01 State: UP
Address: Label: host2_2 State: UP
Network Name: net_ether_01 State: UP
Address: 10.2.100.2 Label: host2_l1_svc1 State: UP
Address: 10.2.101.2 Label: host2_l1_svc2 State: UP
Address: 10.2.11.2 Label: host2_l1_boot2 State: UP
Address: 10.2.1.22 Label: host2_l1_boot1 State: UP
Network Name: net_ether_02 State: UP
Address: 10.2.12.2 Label: host2_l2_boot2 State: UP
Address: 10.2.2.2 Label: host2_l2_boot1 State: UP
Address: 10.2.200.2 Label: host2_l2_svc State: UP
Cluster Name: test_cluster
Resource Group Name: rg_diskhbmulti_01
Startup Policy: Online On All Available Nodes
Fallover Policy: Bring Offline (On Error Node Only)
Fallback Policy: Never Fallback
Site Policy: ignore
Node Group State
---------------------------- ---------------
host1 ONLINE
host2 ONLINE
Resource Group Name: host1_RG
Startup Policy: Online On Home Node Only
Fallover Policy: Fallover To Next Priority Node In The List
Fallback Policy: Fallback To Higher Priority Node In The List
Site Policy: ignore
Node Group State
---------------------------- ---------------
host1 ONLINE
host2 OFFLINE
Resource Group Name: host2_RG
Startup Policy: Online On Home Node Only
Fallover Policy: Fallover To Next Priority Node In The List
Fallback Policy: Fallback To Higher Priority Node In The List
Site Policy: ignore
Node Group State
---------------------------- ---------------
host2 ONLINE
host1 OFFLINE
2.2.4.clstat检查
clstat可以实时监控HACMP的状态,及时确认显示为UP,STABLE,否则根据实际情况进行分析处理。
[host1][root][/]>/usr/sbin/cluster/clstat
clstat - HACMP Cluster Status Monitor
-------------------------------------
Cluster: test_cluster (1572117373)
Mon Sep 16 13:38:31 GMT+08:00 2013
State: UP Nodes: 2
SubState: STABLE
Node: host1 State: UP
Interface: host1_l2_boot1 (2) Address: 10.2.2.1
State: UP
Interface: host1_l1_boot2 (1) Address: 10.2.11.1
State: UP
Interface: host1_l2_boot2 (2) Address: 10.2.12.1
State: UP
Interface: host1_l1_boot1 (1) Address: 10.2.1.21
State: UP
Interface: host1_1 (0) Address: 0.0.0.0
State: UP
Interface: host1_l1_svc1 (1) Address: 10.2.100.1
State: UP
Interface: host1_l1_svc2 (1) Address: 10.2.101.1
State: UP
Interface: host1_l2_svc (2) Address: 10.2.200.1
State: UP
Resource Group: host1_RG State: On line
Resource Group: rg_diskhbmulti_01 State: On line
Node: host2 State: UP
Interface: host2_l2_boot1 (2) Address: 10.2.2.2
State: UP
Interface: host2_l1_boot2 (1) Address: 10.2.11.2
State: UP
Interface: host2_l2_boot2 (2) Address: 10.2.12.2
State: UP
Interface: host2_l1_boot1 (1) Address: 10.2.1.22
State: UP
Interface: host2_2 (0) Address: 0.0.0.0
State: UP
Interface: host2_l1_svc1 (1) Address: 10.2.100.2
State: UP
Interface: host2_l1_svc2 (1) Address: 10.2.101.2
State: UP
Interface: host2_l2_svc (2) Address: 10.2.200.2
State: UP
Resource Group: host2_RG State: On line
Resource Group: rg_diskhbmulti_01 State: On line
************************ f/forward, b/back, r/refresh, q/quit *****************
2.2.5.cldisp检查:
这是从资源的角度做一个查看,可以看到相关资源组的信息是否正确,同样是状态应都为up,stable,online。
[host1][root][/]#/usr/es/sbin/cluster/utilities/cldisp
Cluster: test_cluster
Cluster services: active
State of cluster: up
Substate: stable
#############
APPLICATIONS
#############
Cluster test_cluster provides the following applications: host1_app host2_app
Application: host1_app
host1_app is started by /usr/sbin/cluster/app/start_host1
host1_app is stopped by /usr/sbin/cluster/app/stop_host1
No application monitors are configured for host1_app.
This application is part of resource group 'host1_RG'.
Resource group policies:
Startup: on home node only
Fallover: to next priority node in the list
Fallback: if higher priority node becomes available
State of host1_app: online
Nodes configured to provide host1_app: host1 {up} host2 {up}
Node currently providing host1_app: host1 {up}
The node that will provide host1_app if host1 fails is: host2
Resources associated with host1_app:
Service Labels
host1_l1_svc1(10.2.100.1) {online}
Interfaces configured to provide host1_l1_svc1:
host1_l1_boot1 {up}
with IP address: 10.2.1.21
on interface: en0
on node: host1 {up}
on network: net_ether_01 {up}
host1_l1_boot2 {up}
with IP address: 10.2.11.1
on interface: en2
on node: host1 {up}
on network: net_ether_01 {up}
host2_l1_boot2 {up}
with IP address: 10.2.11.2
on interface: en2
on node: host2 {up}
on network: net_ether_01 {up}
host2_l1_boot1 {up}
with IP address: 10.2.1.22
on interface: en0
on node: host2 {up}
on network: net_ether_01 {up}
host1_l1_svc2(10.2.101.1) {online}
Interfaces configured to provide host1_l1_svc2:
host1_l1_boot1 {up}
with IP address: 10.2.1.21
on interface: en0
on node: host1 {up}
on network: net_ether_01 {up}
host1_l1_boot2 {up}
with IP address: 10.2.11.1
on interface: en2
on node: host1 {up}
on network: net_ether_01 {up}
host2_l1_boot2 {up}
with IP address: 10.2.11.2
on interface: en2
on node: host2 {up}
on network: net_ether_01 {up}
host2_l1_boot1 {up}
with IP address: 10.2.1.22
on interface: en0
on node: host2 {up}
on network: net_ether_01 {up}
host1_l2_svc(10.2.200.1) {online}
Interfaces configured to provide host1_l2_svc:
host1_l2_boot1 {up}
with IP address: 10.2.2.1
on interface: en1
on node: host1 {up}
on network: net_ether_02 {up}
host1_l2_boot2 {up}
with IP address: 10.2.12.1
on interface: en3
on node: host1 {up}
on network: net_ether_02 {up}
host2_l2_boot2 {up}
with IP address: 10.2.12.2
on interface: en3
on node: host2 {up}
on network: net_ether_02 {up}
host2_l2_boot1 {up}
with IP address: 10.2.2.2
on interface: en1
on node: host2 {up}
on network: net_ether_02 {up}
Shared Volume Groups:
host1vg
Application: host2_app
host2_app is started by /usr/sbin/cluster/app/start_host2
host2_app is stopped by /usr/sbin/cluster/app/stop_host2
No application monitors are configured for host2_app.
This application is part of resource group 'host1_RG'.
Resource group policies:
Startup: on home node only
Fallover: to next priority node in the list
Fallback: if higher priority node becomes available
State of host2_app: online
Nodes configured to provide host2_app: host1 {up} host2 {up}
Node currently providing host2_app: host1 {up}
The node that will provide host2_app if host1 fails is: host2
Resources associated with host2_app:
Service Labels
host1_l1_svc1(10.2.100.1) {online}
Interfaces configured to provide host1_l1_svc1:
host1_l1_boot1 {up}
with IP address: 10.2.1.21
on interface: en0
on node: host1 {up}
on network: net_ether_01 {up}
host1_l1_boot2 {up}
with IP address: 10.2.11.1
on interface: en2
on node: host1 {up}
on network: net_ether_01 {up}
host2_l1_boot2 {up}
with IP address: 10.2.11.2
on interface: en2
on node: host2 {up}
on network: net_ether_01 {up}
host2_l1_boot1 {up}
with IP address: 10.2.1.22
on interface: en0
on node: host2 {up}
on network: net_ether_01 {up}
host1_l1_svc2(10.2.101.1) {online}
Interfaces configured to provide host1_l1_svc2:
host1_l1_boot1 {up}
with IP address: 10.2.1.21
on interface: en0
on node: host1 {up}
on network: net_ether_01 {up}
host1_l1_boot2 {up}
with IP address: 10.2.11.1
on interface: en2
on node: host1 {up}
on network: net_ether_01 {up}
host2_l1_boot2 {up}
with IP address: 10.2.11.2
on interface: en2
on node: host2 {up}
on network: net_ether_01 {up}
host2_l1_boot1 {up}
with IP address: 10.2.1.22
on interface: en0
on node: host2 {up}
on network: net_ether_01 {up}
host1_l2_svc(10.2.200.1) {online}
Interfaces configured to provide host1_l2_svc:
host1_l2_boot1 {up}
with IP address: 10.2.2.1
on interface: en1
on node: host1 {up}
on network: net_ether_02 {up}
host1_l2_boot2 {up}
with IP address: 10.2.12.1
on interface: en3
on node: host1 {up}
on network: net_ether_02 {up}
host2_l2_boot2 {up}
with IP address: 10.2.12.2
on interface: en3
on node: host2 {up}
on network: net_ether_02 {up}
host2_l2_boot1 {up}
with IP address: 10.2.2.2
on interface: en1
on node: host2 {up}
on network: net_ether_02 {up}
Shared Volume Groups:
host1vg
This application is part of resource group 'host2_RG'.
Resource group policies:
Startup: on home node only
Fallover: to next priority node in the list
Fallback: if higher priority node becomes available
State of host2_app: online
Nodes configured to provide host2_app: host2 {up} host1 {up}
Node currently providing host2_app: host2 {up}
The node that will provide host2_app if host2 fails is: host1
Resources associated with host2_app:
Service Labels
host2_l1_svc1(10.2.100.2) {online}
Interfaces configured to provide host2_l1_svc1:
host2_l1_boot2 {up}
with IP address: 10.2.11.2
on interface: en2
on node: host2 {up}
on network: net_ether_01 {up}
host2_l1_boot1 {up}
with IP address: 10.2.1.22
on interface: en0
on node: host2 {up}
on network: net_ether_01 {up}
host1_l1_boot1 {up}
with IP address: 10.2.1.21
on interface: en0
on node: host1 {up}
on network: net_ether_01 {up}
host1_l1_boot2 {up}
with IP address: 10.2.11.1
on interface: en2
on node: host1 {up}
on network: net_ether_01 {up}
host2_l1_svc2(10.2.101.2) {online}
Interfaces configured to provide host2_l1_svc2:
host2_l1_boot2 {up}
with IP address: 10.2.11.2
on interface: en2
on node: host2 {up}
on network: net_ether_01 {up}
host2_l1_boot1 {up}
with IP address: 10.2.1.22
on interface: en0
on node: host2 {up}
on network: net_ether_01 {up}
host1_l1_boot1 {up}
with IP address: 10.2.1.21
on interface: en0
on node: host1 {up}
on network: net_ether_01 {up}
host1_l1_boot2 {up}
with IP address: 10.2.11.1
on interface: en2
on node: host1 {up}
on network: net_ether_01 {up}
host2_l2_svc(10.2.200.2) {online}
Interfaces configured to provide host2_l2_svc:
host2_l2_boot2 {up}
with IP address: 10.2.12.2
on interface: en3
on node: host2 {up}
on network: net_ether_02 {up}
host2_l2_boot1 {up}
with IP address: 10.2.2.2
on interface: en1
on node: host2 {up}
on network: net_ether_02 {up}
host1_l2_boot1 {up}
with IP address: 10.2.2.1
on interface: en1
on node: host1 {up}
on network: net_ether_02 {up}
host1_l2_boot2 {up}
with IP address: 10.2.12.1
on interface: en3
on node: host1 {up}
on network: net_ether_02 {up}
Shared Volume Groups:
host2vg
#############
TOPOLOGY
#############
test_cluster consists of the following nodes: host1 host2
host1
Network interfaces:
host1_1 {up}
device: /dev/mndhb_lv_01
on network: net_diskhbmulti_01 {up}
host1_l1_boot1 {up}
with IP address: 10.2.1.21
on interface: en0
on network: net_ether_01 {up}
host1_l1_boot2 {up}
with IP address: 10.2.11.1
on interface: en2
on network: net_ether_01 {up}
host1_l2_boot1 {up}
with IP address: 10.2.2.1
on interface: en1
on network: net_ether_02 {up}
host1_l2_boot2 {up}
with IP address: 10.2.12.1
on interface: en3
on network: net_ether_02 {up}
host2
Network interfaces:
host2_2 {up}
device: /dev/mndhb_lv_01
on network: net_diskhbmulti_01 {up}
host2_l1_boot2 {up}
with IP address: 10.2.11.2
on interface: en2
on network: net_ether_01 {up}
host2_l1_boot1 {up}
with IP address: 10.2.1.22
on interface: en0
on network: net_ether_01 {up}
host2_l2_boot2 {up}
with IP address: 10.2.12.2
on interface: en3
on network: net_ether_02 {up}
host2_l2_boot1 {up}
with IP address: 10.2.2.2
on interface: en1
on network: net_ether_02 {up}
[host1][root][/]#
2.2.6./etc/hosts环境检查
正常情况下,2台互备的/etc/hosts应该是一致的,当然如果是主备机方式,可能备机会多些IP地址和主机名。通过对比2个文件的不同,可以确认是否存在问题。
[host1][root][/]>rsh host2 cat /etc/hosts >/tmp/host2_hosts
[host1][root][/]>diff /etc/hosts /tmp/host2_hosts
2.2.7.脚本检查需要注意以下事项:
1. 应用的变更需要及时修正脚本,两边的脚本需要及时同步,并及时申请时间测试。
2. 上一点需要维护人员充分与应用人员沟通,运行环境的任何变更必须通过维护人员实施。
3. 维护人员启停应用要养成使用这些脚本启停系统的习惯,尽量避免手工启停。
[host1][root][/home/scripts]>rsh host2 "cd /home/scripts;ls -l host1 host2 comm" >/tmp/host2_scripts
[host1][root][/home/scripts]> ls -l host1 host2 comm" >/tmp/host1_scripts
[host1][root][/]>diff /tmp/host1_scripts /tmp/host2_scripts
2.2.8.用户检查正常情况下,2台互备的HA使用到的用户情况应该是一致的,当然如果是主备机方式,可能备机会多些用户。通过对比2节点的配置不同,可以确认是否存在问题。
[host1][root][/]>
rsh host2 lsuser -f orarun,orarunc,tuxrun,bsx1,xcom >/tmp/host2_users
[host1][root][/]>
lsuser -f orarun,orarunc,tuxrun,bsx1,xcom >/tmp/host2_users >/tmp/host1_users
[host1][root][/]>diff /tmp/host1_user /tmp/host2_user
注:两边的必然有些不同,如上次登录时间等等,只要主要部分相同就可以了。
还有两边 .profile的对比,用户环境的对比。
[host1][root][/]>rsh host2 su - orarun -c set >/tmp/host2.set
[host1][root][/]> su - orarun -c set >/tmp/host1.set
[host1][root][/]>diff /tmp/host1.set /tmp/host2.set
2.2.9. 心跳检查
由于心跳在HACMP启动后一直由HACMP在用,所以需要强制停掉HACMP进行检查。
1)察看心跳服务:
从topsvcs可以看到网络的状况,也包括心跳网络,报错为零或比率远低于1%。
[host2][root][/]#lssrc -ls topsvcs
Subsystem Group PID Status
topsvcs topsvcs 9371838 active
Network Name Indx Defd Mbrs St Adapter ID Group ID
net_ether_01_0 [ 0] 2 2 S 10.2.1.22 10.2.1.22
net_ether_01_0 [ 0] en0 0x42366504 0x42366d24
HB Interval = 1.000 secs. Sensitivity = 10 missed beats
Missed HBs: Total: 0 Current group: 0
Packets sent : 15690 ICMP 0 Errors: 0 No mbuf: 0
Packets received: 18345 ICMP 0 Dropped: 0
NIM's PID: 7929856
net_ether_01_1 [ 1] 2 2 S 10.2.11.2 10.2.11.2
net_ether_01_1 [ 1] en2 0x42366505 0x42366d25
HB Interval = 1.000 secs. Sensitivity = 10 missed beats
Missed HBs: Total: 0 Current group: 0
Packets sent : 15690 ICMP 0 Errors: 0 No mbuf: 0
Packets received: 18347 ICMP 0 Dropped: 0
NIM's PID: 9044088
net_ether_02_0 [ 2] 2 2 S 10.2.2.2 10.2.2.2
net_ether_02_0 [ 2] en1 0x42366506 0x42366d26
HB Interval = 1.000 secs. Sensitivity = 10 missed beats
Missed HBs: Total: 0 Current group: 0
Packets sent : 15688 ICMP 0 Errors: 0 No mbuf: 0
Packets received: 18345 ICMP 0 Dropped: 0
NIM's PID: 6881402
net_ether_02_1 [ 3] 2 2 S 10.2.12.2 10.2.12.2
net_ether_02_1 [ 3] en3 0x42366507 0x42366d27
HB Interval = 1.000 secs. Sensitivity = 10 missed beats
Missed HBs: Total: 0 Current group: 0
Packets sent : 15687 ICMP 0 Errors: 0 No mbuf: 0
Packets received: 18344 ICMP 0 Dropped: 0
NIM's PID: 6684902
diskhbmulti_0 [ 4] 2 2 S 255.255.10.1 255.255.10.1
diskhbmulti_0 [ 4] rmndhb_lv_01.2_1 0x8236653e 0x82366d48
HB Interval = 3.000 secs. Sensitivity = 6 missed beats
Missed HBs: Total: 0 Current group: 0
Packets sent : 5021 ICMP 0 Errors: 0 No mbuf: 0
Packets received: 4754 ICMP 0 Dropped: 0
NIM's PID: 6553654
2 locally connected Clients with PIDs:
haemd(7602388) hagsd(9699456)
Fast Failure Detection available but off.
Dead Man Switch Enabled:
reset interval = 1 seconds
trip interval = 36 seconds
Client Heartbeating Disabled.
Configuration Instance = 1
Daemon employs no security
Segments pinned: Text Data.
Text segment size: 862 KB. Static data segment size: 1497 KB.
Dynamic data segment size: 8897. Number of outstanding malloc: 269
User time 1 sec. System time 0 sec.
Number of page faults: 151. Process swapped out 0 times.
Number of nodes up: 2. Number of nodes down: 0.
2)串口心跳检查:
u 察看tty速率
确认速率不超过9600
[host1][root][/]>stty -a </dev/tty0
[host2][root][/]>cat /etc/hosts >/dev/tty0
host1上显示
speed 9600 baud; 0 rows; 0 columns;
eucw 1:1:0:0, scrw 1:1:0:0:
….
u 检查连接和配置
[host1][root][/]>host1: cat /etc/hosts>/dev/tty0
[host2][root][/]>host2:cat</dev/tty0
在host2可看到host1上/etc/hosts的内容。
同样反向检测一下。
3)串口心跳检查:
利用dhb_read确认磁盘的心跳连接
[host1][root][/]#/usr/sbin/rsct/bin/dhb_read -p hdisk5 -r
DHB CLASSIC MODE
First node byte offset: 61440
Second node byte offset: 62976
Handshaking byte offset: 65024
Test byte offset: 64512
Receive Mode:
Waiting for response . . .
Magic number = 0x87654321
Magic number = 0x87654321
Magic number = 0x87654321
Magic number = 0x87654321
Magic number = 0x87654321
Magic number = 0x87654321
Magic number = 0x87654321
Link operating normally
[host2][root][/]#/usr/sbin/rsct/bin/dhb_read -p hdisk5 -r
DHB CLASSIC MODE
First node byte offset: 61440
Second node byte offset: 62976
Handshaking byte offset: 65024
Test byte offset: 64512
Receive Mode:
Waiting for response . . .
Magic number = 0x87654321
Magic number = 0x87654321
Magic number = 0x87654321
....
Magic number = 0x87654321
Magic number = 0x87654321
Link operating normally
[host1][root][/]#/usr/sbin/rsct/bin/dhb_read -p hdisk5 -t
DHB CLASSIC MODE
First node byte offset: 61440
Second node byte offset: 62976
Handshaking byte offset: 65024
Test byte offset: 64512
Transmit Mode:
Magic number = 0x87654321
Detected remote utility in receive mode. Waiting for response . . .
Magic number = 0x87654321
Magic number = 0x87654321
Link operating normally
最后报Link operating normally.正常即可,同样反向也检测一下。
2.2.10. errpt的检查
虽然有了以上许多检查,但我们最常看的errpt不要忽略,因为有些报错,需要大家引起注意,由于crontab里HACMP会增加这样一行:
0 0 * * * /usr/es/sbin/cluster/utilities/clcycle 1>/dev/null 2>/dev/null # HACMP for AIX Logfile rotation
即实际上每天零点,系统会自动执行HACMP的检查,如果发现问题,会在errpt看到。
除了HACMP检查会报错,其他运行过程中也有可能报错,大都是由于心跳连接问题或负载过高导致HACMP进程无法处理,需要引起注意,具体分析解决。
由于维护的过程出现的情况远比集成实施阶段要复杂,即使红皮书也不能覆盖所有情况。这里只就大家常见的情况加以说明,对于更为复杂或者更为少见的情况,还是请大家翻阅红皮书,实在不行计划停机重新配置也许也是一个快速解决问题的笨方法。
这里的变更原则上是不希望停机,但实际上HACMP的变更,虽然说部分支持DARE(dynamic reconfiguration),部分操作支持Force stop 完成,我们还是建议有条件的话停机完成。
对于动态DARE,我不是非常赞成使用,因为使用不当会造成集群不可控,危险性更大。我一般喜欢使用先强制停止HACMP,再进行以下操作,结束同步确认后再start HACMP。
2.3.1.卷组变更-增加磁盘到使用的VG里:
注意,pvid一定要先认出来,否则盘会没有或不正常。
1. 集群的各个节点机器运行cfgmgr,设置pvid
[host1][root][/]>cfgmgr
[host1][root][/]>lspv
….
hdisk2 00f6f1569990a1ef host1vg
hdisk3 00f6f1569990a12c host2vg
hdisk4 none none
[host1][root][/]>chdev -l hdisk2 -a pv=yes
[host1][root][/]>lspv
….
hdisk4 00c1eedffc677bfe none
在host2上也要做同样操作。
2. 运行C-SPOC增加盘到host2vg:
smitty hacmp->System Management (C-SPOC)
-> Storage
-> Volume Groups
-> Set Characteristics of a Volume Group
-> Add a Volume to a Volume Group
选择VG、磁盘增加即可
Add a Volume to a Volume Group
Type or select values in entry fields.
Press Enter AFTER making all desired changes.
[Entry Fields]
VOLUME GROUP name host2vg
Resource Group Name host2_RG
Node List host1,host2
VOLUME names hdisk4
Physical Volume IDs 00f6f1562fd2853e
完成后两边都可看到
hdisk3 00f6f1569990a12c host2vg active
hdisk4 00f6f1562fd2853e host2vg active
2.3.2.逻辑卷lv变更1) lv本身变更:
目前支持增加lv的拷贝,减少,增加空间,改名;
这里以裸设备lv增加空间举例:
smitty hacmp->System Management (C-SPOC)
-> Storage
-> Shared Logical Volumes
>Set Characteristics of a Logical Volume
-> Increase the Size of a Logical Volume
2) lv属性变更
效果和单机环境一致,但还是建议慎重操作,充分考虑改动后对业务的影响:
smitty hacmp->System Management (C-SPOC)
-> Storage
->Logical Volume
->Change a Logical Volume
->Change a Logical Volume on the Cluster选择lv
Volume Group Name host2vg
Resource Group Name host2_RG
* Logical volume NAME ora11runlv
Logical volume TYPE [jfs2]
POSITION on physical volume outer_middle
RANGE of physical volumes minimum
MAXIMUM NUMBER of PHYSICAL VOLUMES [32]
to use for allocation
Allocate each logical partition copy yes
on a SEPARATE physical volume?
RELOCATE the logical volume during yes
RELOCATE the logical volume during yes
reorganization?
Logical volume LABEL [/ora11run]
MAXIMUM NUMBER of LOGICAL PARTITIONS [512]
SCHEDULING POLICY for writing logical parallel
partition copies
PERMISSIONS read/write
Enable BAD BLOCK relocation? yes
Enable WRITE VERIFY? no
Mirror Write Consistency? active
Serlialize I/O? no
2.3.3. 文件系统变更
smitty hacmp->System Management (C-SPOC)
-> Storage
- >File Systems
->Change / Show Characteristics of a File System
Volume group name host1vg
Resource Group Name host1_RG
* Node Names host2,host1
* File system name /ora11runc
NEW mount point [/ora11runc] /
SIZE of file system
Unit Size 512bytes +
Number of Units [10485760] #
Mount GROUP []
Mount AUTOMATICALLY at system restart? no +
PERMISSIONS read/write +
Mount OPTIONS []
Mount AUTOMATICALLY at system restart? no +
PERMISSIONS read/write +
Mount OPTIONS [] +
Start Disk Accounting? no +
Block Size (bytes) 4096
Inline Log? no
Inline Log size (MBytes) [0] #
Extended Attribute Format [v1]
ENABLE Quota Management? no +
Allow Small Inode Extents? [yes] +
Logical Volume for Log host1_loglv
2.3.4.增加服务IP地址(仅DARE支持)1) 修改/etc/hosts,增加以下行
10.66.201.1 host1_l2_svc2
10.66.201.2 host2_l2_svc2
注意:2边都要增加。
2) 增加服务地址
smitty hacmp->Extended Configuration
-> HACMP Extended Resources Configuration
-> Configure HACMP Service IP Labels/Addresses
-> Add a Service IP Label/Address
-> Configurable on Multiple Nodes选择网络
-> Add a Service IP Label/Address configurable on Multiple Nodes (extended)
Type or select values in entry fields.
Press Enter AFTER making all desired changes.
* IP Label/Address host1_svc2
* Network Name net_ether_02
Alternate HW Address to accompany IP Label/Address []
同样增加host2_svc2
2)3) 修正资源组
smitty hacmp->Extended Configuration
->Extended Resource Configuration
->HACMP Extended Resource Group Configuration
->Change/Show Resources and Attributes for a Resource Group
->Change/Show All Resources and Attributes for a Resource Group
4) HACMP同步
触发新增服务ip生效。
这时netstat -in,可以看到地址生效了。
2.3.5. 修改服务IP地址
如果应用服务使用的IP地址,自然是需要停止应用进行修改。比如要将原地址10.2.200.x改为10.2.201.x,路由改为10.2.201.254步骤如下:
1. 正常停止HACMP
smitty clstop ->Bring Resource Groups offline
2. 所有节点修改/etc/hosts将服务地址修改为需要的地址
10.2.201.1 host1_l2_svc host1
10.2.201.2 host2_l2_svc host2
注意同时要修正 /usr/es/sbin/cluster/etc/clhosts
3. 修改启动脚本的路由部分(如果需要)
GATEWAY=10.2.201.254
4. 在一个节点修改HACMP的配置
smitty hacmp->Extended Configuration
-> Extended Resource Configuration
->HACMP Extended Resources Configuration
->Configure HACMP Service IP Labels/Addresses
->Change/Show a Service IP Label/Address选择host1_l2_svc
不做修改,直接回车即可,同样修改host2_l2_svc。
smitty hacmp->Extended Configuration
->Extended Resource Configuration
->HACMP Extended Resource Group Configuration
->Change/Show Resources and Attributes for a Resource Group
->Change/Show All Resources and Attributes for a Resource Group
选择host1_RG
不做修改,直接回车即可,同样修改host2_RG
5. 同步HACMP
6. 重新启动HACMP确认
触发新服务IP地址生效。
注:如果修改的不是应用服务要用的地址,或者修改期间对该地址的服务可以暂停,则可以将1改为强制停止,增加第7步,整个过程可以不停应用服务。
7.去除原有服务IP地址
netstat -in找到该服务IP地址所在网卡比如为en2
ifconfig en2 alias delete 10.2.200.1
2.3.6.boot地址变更1. smitty tcpip修改网卡的地址
2. 修改/etc/hosts的boot地址,
注意同时要修正 /usr/es/sbin/cluster/etc/clhosts
3. 修改HACMP配置
smitty hacmp ->Extended Configuration
-> Extended Topology Configuration
-> Extended Topology Configuration
Change/Show a Communication Interface
Node Name [bgbcb04]
Network Interface en1
IP Label/Address host1_boot1
Network Type ether
* Network Name [net_ether_01]
不做修改,直接回车即可,同样修改其他boot地址。
4. 同步HACMP
5. 重新启动HACMP确认
注意修改启动参数使得启动时重新申请资源,触发新boot IP地址生效,否则clstat看到的boot地址将是down。
2.3.7.用户变更修改用户口令
由于安全策略的原因,系统可能需要更改口令,利用HACMP会方便不少,也避免切换过去后因时隔太久,想不起口令需要强制修改的烦恼。
唯一设计不合理的是,必须root才能使用这个功能。
smitty HACMP ->Extended Configuration
-> Security and Users Configuration
-> Passwords in an HACMP cluster
-> Change a User's Password in the Cluster
Selection nodes by resource group host2_RG
*** No selection means all nodes! ***
* User NAME [orarun]
User must change password on first login? false
此时需要你输入新口令更改:
COMMAND STATUS
Command: running stdout: no stderr: no
Before command completion, additional instructions may appear below.
orarun's New password:
Enter the new password again:
OK即成功
修改用户属性
以下步骤可变更用户属性,值得注意的是,虽然可以直接修改用户的UID,但实际上和在单独的操作系统一样,不会自动修改该用户原有的文件和目录的属性,必须事后自己修改,所以建议UID在规划阶段就早做合理规划。
smitty HACMP ->Extended Configuration
-> Security and Users Configuration
->Users in an HACMP cluster
-> Change / Show Characteristics of a User in the Cluster
选择资源组和用户
除开头1行,其他使用均等同于独立操作系统。
Change User Attributes on the Cluster
Resource group eai1d0_RG
* User NAME test
User ID [301]
ADMINISTRATIVE USER? false
….
第五部分--脚本篇HACMP作用,在于关键时刻能根据发生的情况自动通过预先制定好的策略实施处理-如切换,使得用户短暂的中断即可继续使用。而对于用户来说,“应用可用”才是HACMP切换成功的标志,而这一点不光是HACMP配置本身,还大大倚赖于启停脚本的可用性。
目前IBM的PowerHA6.1.08以后,趋于稳定,BUG很少,这使得用户概念的HACMP切换不成功的主要原因是启停脚本的问题,而很多时候,脚本的问题是非常隐蔽和难以测试的,所以在编写启停脚本时需要考虑周全,系统上线后要仔细维护。
通过多年的实践,我们形成了自己的一套脚本编制方式,共享出来,供大家参考。
2.1. 脚本规划2.1.1.启停方式
对于停止脚本,通过后台启动,前台检查的方式进行,并使用清理VG的进程,确保停止成功。
对于启动脚本,完全放在后台,不影响HACMP的切换。
由于启停是由启停各个部件启动组成的,如host1的启停就是启停tuxedo和xom软件组成,host2的启停就是有启动DB和listener组成。我们把主机的启动分割为各个部分,这样综合写出共性的公用脚本程序,这样虽然第一次编写测试这些公用程序会花费大量的时间和精力,但最终将大大减轻管理员的重复劳动,简化了脚本的编写,保证了脚本的质量。
2.1.2.文件存放目录表
|
目录 |
用途 |
举例 |
|
/usr/sbin/cluster/app |
HA启停脚本存放 |
|
|
/usr/sbin/cluster/app/log |
启停应用的详细log存放 |
|
|
/home/scripts/`hostname` |
应用启停脚本存放 |
/home/scripts/host1 |
|
/tmp |
存放启停应用的log |
/tmp/ha_app.out |
2.1.3.文件命名表:
以主机名为特征进行命名,这样方便和区分。
|
脚本 |
命名规则 |
举例 |
|
HA启动脚本 |
start_`hostname` |
start_host1 |
|
应用启动脚本 |
start_`hostname`_app |
start_host1_app |
|
HA停止脚本 |
stop_`hostname` |
stop_host2 |
|
应用停止脚本 |
stop_`hostname`_app |
stop_host2_app |
|
启停应用log |
/tmp/ha_app.out |
|
|
启动应用详细log |
start_`hostname`_app`yyyymmddHHMM`log |
start_host1_app200712241722.log |
|
停止应用详细log |
stop_`hostname`_app`yyyymmddHHMM`log |
stop_host1_app200712241722.log |
2.1.4.启停跟踪
为了便于跟踪和阅读,应用的启停log不写入/var/hacmp/log/hacmp.out,而是另行输出到单独的log。一般情况下,管理员只需跟踪/tmp/ha_app.out即可,一直等不到结束,再查看/usr/sbin/cluster/app/log下详细log。
[host2][root][/]>tail -f /tmp/ha_app.out
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Starting--- host2 at Tue Dec 18 11:17:51 BEIST 2007
Waiting------- DB testdb --------- start,Press any key to cancel..
DB testdb is started!
Waiting------- listener testdb --------- start,Press any key to cancel..
testdb -- LISTENER is started!
Waiting------- listener testdb port 1521--------- start,Press any key to cancel..
LISTENER testdb port 1521 is listening!
start eai1d1 successful! at Tue Dec 18 11:20:43 BEIST 2007
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
[host2][root][/]>cd /usr/sbin/cluster/app
[host2][root][/]>more start_host2_app200712181117.log
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Starting--- eai1d1 at Mon Dec 24 16:06:35 BEIST 2007
Mon Dec 24 16:06:35 BEIST 2007
Waiting------- DB eaiz1dev --------- start,Press any key to cancel..
SQL*Plus: Release 10.2.0.2.0 - Production on Mon Dec 24 16:06:35 2007
Copyright (c) 1982, 2005, Oracle. All Rights Reserved.
Connected to an idle instance.
SQL> ORACLE instance started.
Total System Global Area 1543503872 bytes
Fixed Size 2071488 bytes
Variable Size 369099840 bytes
Database Buffers 1157627904 bytes
Redo Buffers 14704640 bytes
....Database mounted.
.Database opened.
SQL> Disconnected from Oracle Database 10g Enterprise Edition Release 10.2.0.2.0 - 64bit Production
……
2.1.5.编写注意事项:值得注意的是,经过测试和实际使用发现,由HA启动脚本时,如有嵌套,相对目录执行程序将不能生效,必须写成绝对路径。如下面的情况将导致错误:
start_host1: nohup /home/scripts/host1/start_host1_app &
start_host1_app: /home/scripts/comm/start_db.sh orarun testdb 1521
start_db.sh: cd /home/scripts/comm
check_db_main.sh testdb
check_db_main.sh not found。
需要改写为
start_db.sh: /home/scripts/comm/check_db_main.sh testdb
2.2. 启动脚本
由于HACMP的启动和应用的启动可以分开,为避免应用脚本的启动不正常导致HACMP的报错,建议将HACMP的启动脚本简化,将启动应用的部分放在另一个应用启动脚本里。
基于规划,start_host2_app的启动脚本使用了公用程序start_db.sh 和wait_db_start.sh,源代码如下,供大家参考:
start_db.sh的代码如下:
#start_db.sh oracle_sid listener_name
ORACLE_SID=$1
sqlplus " / as sysdba"<< EOF
startup
EOF
lsnrctl start $2
wait_db_start.sh的代码如下:
wait_db.sh oracle_user oracle_sid listner_port
#return code: 1---press key canceled
waitout ()
{
printf "Waiting------- ${1} ${2} ${3}--------- start,Press any key to cancel."
}
#main
CURRENT_PATH=`pwd`
SCRIPTS_PATH=`dirname ${0}`
cd $SCRIPTS_PATH
waitout DB $2
i=1
while [ $i -gt 0 ]
do
waitkey
$SCRIPTS_PATH/check_db_main.sh $1 $2
i=$?
done
waitout listener $2
i=1
while [ $i -gt 0 ]
do
waitkey
$SCRIPTS_PATH/check_db_listener.sh $1 $2 $4
i=$?
done
waitout listener $2 "port $3"
i=1
while [ $i -gt 0 ]
do
waitkey
$SCRIPTS_PATH/check_port.sh $3
i=$?
done
echo "nLISTENER $2 port $3 is listening!"
cd $CURRENT_PATH
exit 0
实际使用start_host1代码如下:
#start_host1
MACHINE=host1
GATEWAY=10.2.1.254
HA_LOG=log/start_"$MACHINE"_app`date +%C%y%m%d%H%M`.log
SCRIPTS_PATH=`dirname ${0}`
if [ "$SCRIPTS_PATH" = "." ];then
SCRIPTS_PATH=`pwd`
fi
if [ `hostname` = "$MACHINE" ]; then
route delete 0
route add 0 $GATEWAY
fi
> $SCRIPTS_PATH/$HA_LOG
nohup /home/scripts/comm/tail_log.sh start_app $SCRIPTS_PATH/$HA_LOG "!!!!!!!!!!!!|started!|Waiting---|listening!|starting---|successful!" "successful!" >>/tmp/ha_app.out &
sleep 1
nohup /home/scripts/$MACHINE/start_"$MACHINE"_app ha >$HA_LOG &
exit 0
2.3. 停止脚本由于必须保证应用正常停止,才切换过去,所以停止脚本的正常结束才是HACMP停止应用服务器的成功。
停止脚本需要设定一个等待时间的阀值,超过这个阀值,将进行异常中止脚本的运行。
此外,为了防止停止时出现停不下来的现象,导致HACMP超时报too long广播,需要注意以下停止脚本的编写:
1. 停止数据库脚本停止数据库之前,必须记得先清理掉远程连接的用户,这样才能保证数据库能在可预测的时间内正常停止。
如oracle数据库停止之前,建议增加以下代码:
ps -ef|grep ora|grep $ORACLE_SID|grep "LOCAL=NO"|awk '{print "kill -9 "$2}'|sh
如果数据库超过一段时间仍停不下来,必须启动异常停止脚本
2. 最后加上清理文件系统的脚本
这一点很容易被忽略,因为有时即使应用正常停止,以下原因都可能导致导致HACMP不能umount这个文件系统:
u 有用户登录在该文件系统下
u 有其他程序使用了该文件系统下的库文件
u 该文件系统与应用无关,但正在被使用。
结果均会最终导致HACMP停止不了该节点,切换失败。
基于这个原因,我们编写了kill_vg_user.sh,使用起来非常方便有效,都放在/home/scripts/comm下。现提供源代码,供大家使用和指正。
kill_vg_user.sh 代码如下
#kill_vg_user.sh vg_name
#kill_vg_user.sh erpapp_vg
if [ $# -le 0 ] ;then
echo "no para, example:kill_vg_user.sh erpapp_vg "
exit
fi
#main
SCRIPTS_PATH=`dirname ${0}`
df -k|awk '{print $7 }'|grep -v Mounted >/tmp/fs_mounted.txt
for i in `lsvg -l $1 |grep -vE "N/A|vg|MOUNT"|awk '{print $7}'`
do
if [ `grep -c $i /tmp/fs_mounted.txt` -ge 1 ] ; then
echo kill_fs_user.sh $i
$SCRIPTS_PATH/kill_fs_user.sh $i
fi
done
调用的kill_fs_user.sh代码如下
#kill_fs.sh fs_name
#kill_fs.sh /oracle
if [ ` df -k|grep $1|grep -v grep|awk '{print $7}'|grep -v [0-9a-zA-Z]$1|grep -v $1[0-9a-zA-Z_-]|wc -l` -eq 1 ] ;then
fuser -kcux $1
fi
MACHINE=host1
VGNAME=host1vg
HA_LOG=log/stop_"$MACHINE"_app`date +%C%y%m%d%H%M`.log
SCRIPTS_PATH=`dirname ${0}`
if [ "$SCRIPTS_PATH" = "." ];then
SCRIPTS_PATH=`pwd`
fi
cd $SCRIPTS_PATH
>$HA_LOG
/home/scripts/comm/tail_log.sh stop_app $SCRIPTS_PATH/$HA_LOG "!!!!!!!!!!!!!!!!!!|stopped!|Waiting---|stopping---|successful!" "successful!" >>/tmp/ha_app.out &
sleep 1
/home/scripts/$MACHINE/stop_"$MACHINE"_app ha >$HA_LOG 2 >&1#stop_host1
/home/scripts/comm/kill_vg_user.sh $VGNAME
exit 0
2.4. 同步HA的脚本由于HA切换后,切换的时间有可能超过一天,而切换时很可能另一台机器已无法开启,不能拿到最新的crontab和后台相关脚本,所以crontab和脚本最好能每天自动同步。
2.4.1.编写sync_HA.sh
在host1上编写
Ø sync_HA.sh的源代码
OMACHINE=host2
rsh $OMACHINE "cd /home/scripts;tar -cvf ${OMACHINE}_scripts.tar $OMACHINE"
rcp $OMACHINE:/home/scripts/${OMACHINE}_scripts.tar /home/scripts
cd /home/scripts
rm -rf $OMACHINE
tar -xvf ${OMACHINE}_scripts.tar
rcp $OMACHINE:/var/spool/cron/crontabs/root /home/scripts/$OMACHINE/crontab_${OMACHINE}
Ø 修改Crontab生效
###sync crontab
0 0 * * * /home/script/sync_HA.sh >/tmp/sync_HA.log 2>&1
同样在host2上编写,但注意OMACHINE修改为host1。
第六部分--经验篇2.1. 异常情况的人工干预
本文没有详细描述HACMP异常情况的处理,这是因为每个系统每次异常可能情况都不一样,而且一般来说,安装HACMP的系统都是核心系统,给你留的时间会非常短,快速处理的要求更严格。
所以,我们试图找到一个办法,来应对HACMP本身异常99%的异常情况,而对于脚本和系统参数的不匹配,只能通过找出问题所在来处理。
2.1.1.场景1:host1出现问题,但HACMP没有切换过来僵住了1) 快速强制停止host1机器运行
host1:halt -q
2) 确保应用服务继续
host2上使用手工启动host1_RG,
smitty HACMP->System Management (C-SPOC)
-> HACMP Resource Group and Application Management
->Bring a Resource Group Online 选择host1_RG,host2
Bring a Resource Group Online
Type or select values in entry fields.
Press Enter AFTER making all desired changes.
[Entry Fields]
Resource Group to Bring Online host1_RG
Node on Which to Bring Resource Group Online host2
即在host2上启动host1的资源组。
3) 检查和确认应用已可继续
如发现仍然不正常,启动下一场景的第3点处理。
4) 检查和修正问题。
a) host2:强制停止HACMP
b) 重新启动host1,确认无硬件问题
c) 检查HACMP的环境,阅读/var/hacmp/log/hacmp.out等log,看看能否找出问题所在
d) 修正HACMP或其他部分
e) 确认无误申请短暂停机时间,重起HACMP回原
2.1.2.场景2:host1出现问题,HACMP切换过来,但僵住了
由于此场景的起因有很多,3,4点只能根据具体系统来细化,但还是强烈建议每个系统编制一份手工切换手册,详细列明HACMP不可用的情况下如何手工启动应用。以备紧急情况使用。
1) 停止host1机器运行
host1:halt -q
2) host2强制停止HACMP
3) 检查和修正目前状况
HACMP异常情况修正表
|
序号 |
目前状况 |
目前状况 |
修正 |
备注 |
|
1 |
服务IP地址 |
无 |
smitty tcpip手工添加 |
|
|
2 |
vg状况 |
未varyon |
varyonvg手工执行 |
如果锁住加 varyonvg -bu |
|
3 |
fs状况 |
未mount |
mount手工执行 |
如损坏,执行fsck -y |
|
4 |
应用程序状况 |
执行异常 |
强制停止,重起 |
确认1-3 ok再做 |
4) 手工修正目前状况
5) 检查和修正问题
a) 重新启动host1,确认无硬件问题
b) 检查HACMP的环境,阅读/var/hacmp/log/hacmp.out等log,看看能否找出问题所在
c) 修正HACMP或其他部分
d) 确认无误申请短暂停机时间,重起HACMP回原
2.2. 其他有用的经验2.2.1.HACMP自动启动的实现
有的系统,希望开机就把HACMP自动带起,也就不需要人工干预就启动了应用,这需要clstart时指明:
[host1][root][/]>smitty clstart
Start Cluster Services
* Start now, on system restart or both restart
Start Cluster Services on these nodes [host1]
BROADCAST message at startup? true
Startup Cluster Information Daemon? false
Reacquire resources after forced down ? false
这样,HACMP会自动才/etc/initab里增加以下一行
hacmp6000:2:wait:/usr/es/sbin/cluster/etc/rc.cluster -boot -i -A # Bring up Cluster
这样就实现了自动启动HACMP和应用。
如果希望取消这种设定,需要运行clstop:
[host1][root][/]>smitty clstop
Stop Cluster Services
* Stop now, on system restart or both restart
Stop Cluster Services on these nodes [host1]
BROADCAST cluster shutdown? true
*Select an Action on Resource Groups Bring Resource Groups
可以看到/etc/initab里这一行消失了。
2.2.2.HACMP的too long报警广播的修正
在有些系统运行很长时间的情况下,有可能停止的时间会超出我们预期,如oracle数据库的某些资源被交换到Pagespace里。缺省如果超过180s,就会广播报警,直至HACMP异常。这时你可以修正这个参数,以避免广播出现。
smitty HACMP->Extended Configuration
->Extended Event Configuration
->Change/Show Time Until Warning
Max. Event-only Duration (in seconds) [360]
Max. Resource Group Processing Time (in seconds) [360]
Total time to process a Resource Group event 12 minutes and 0 seconds
before a warning is displayed
NOTE: Changes made to this panel must be
propagated to the other nodes by
Verifying and Synchronizing the cluster
同样,修改后需要HACMP同步。
2.2.3.HACMP的DMS问题的修正 DMS(deadman switch)是用来描述系统kernel
extension用的,它可以在系统崩溃前down掉系统,并产生dump 文件,以供日后检查。
DMS存在的目的是为了保护共享外置硬盘及数据,当系统挂起时间长过一定限制时间时,DMS会自动down掉该系统,由HACMP的备份节点接管系统,以保护数据和业务的正常进行,避免潜在的问题,特别是外置磁盘阵列。
errpt确认DMS的发生:
LABEL:
KERNEL_PANIC
IDENTIFIER: 225E3B63
Date/Time: Thu Apr 25 21:26:16
Sequence Number: 609
Machine Id: 0040613A4C00
Node Id: localhost
Class: S
Type: TEMP
Resource Name: PANIC
Descrīption
SOFTWARE PROGRAM ABNORMALLY TERMINATED
Recommended Actions
PERFORM PROBLEM DETERMINATION PROCEDURES
Detail Data
ASSERT STRING
PANIC STRING
DMS起作用的原因主要有以下几点:
Ø 某种应用程序的优先级大于clstrmgr deamon , 导致clstrmgr无法正常reset DMS计数器。
Ø 在系统上存在大量IO 操作, 导致CPU 没有时间相应clstrmgr deamon .
Ø 内存泄漏或溢出问题
Ø 大量的系统错误日志活动。
换句话说,当以上情况出现时,HACMP认为系统崩溃,会自动切换到另一台节点机上去,这是我们想要的结果吗?
一般情况下,原有的缺省设置无需更改。但由于系统运行了较长时间后,负荷可突破原有设计(平均小于45%),而且某些情况下会持续100%,我们就不希望发生切换。如果发生了DMS造成的切换,我们先延长HACMP的确认的时间,即调整心跳线的诊断频率:
smitty HACMP->Extended Topology Configuration
->Configure HACMP Network Modules
-> Change a Network Module using Predefined Values选择r232
* Network Module Name rs232
Description RS232 Serial Protocol
Failure Detection Rate Slow
NOTE: Changes made to this panel must be
propagated to the other nodes by
Verifying and Synchronizing the cluster
同样,记得同步HACMP。
如果还是发生DMS导致的HACMP切换,排除异常后,只好禁用DMS了,这点IBM不推荐,因为有可能造成切换时数据丢失或损坏。
修改rc.cluster 文件增加-D参数:
[host1][root][/]> vi /usr/es/sbin/cluster/etc/rc.cluster
if [ "$VERBOSE_LOGGING" = "high" ]
then
clstart -D -smG $CLINFOD $BCAST
else
clstart -D -smG $CLINFOD $BCAST 2>/dev/console
fi
重起HACMP生效。
2.2.4.snmp的调整(AIX5.3不需要)在aix5.2 下要对snmp 做一些调整才可以看到真正的HACMP的状态。
具体来说, aix 5.2 的 snmp 默认是version 3 :
[host1][root][/]>ls -l |grep snmp
lrwxrwxrwx 1 root system 8 Apr 08 17:55 clsnmp -> clsnmpne
-rwxr-x--- 1 root system 83150 Mar 12 2003 clsnmpne
-rwxr-x--- 1 root system 55110 Mar 12 2003 pppsnmpd
lrwxrwxrwx 1 root system 9 Apr 08 17:55 snmpd -> snmpdv3ne
而HACMP 只支持snmp version 1 . 所以我们要做一下调整:
stopsrc -s snmpd
/usr/sbin/snmpv3_ssw -1startsrc -s snmpd
[host1][root][/usr/sbin]>ls -l |grep snmp
lrwxrwxrwx 1 root system 18 Apr 21 13:40 clsnmp -> /usr/sbin/clsnmpne
-rwxr-x--- 1 root system 83150 Mar 12 2003 clsnmpne
-rwxr-x--- 1 root system 55110 Mar 12 2003 pppsnmpd
lrwxrwxrwx 1 root system 17 Apr 21 13:40 snmpd -> /usr/sbin/snmpdv1
如果觉得我的文章对您有用,请点赞。您的支持将鼓励我继续创作!
赞16作者其他文章
评论 1 · 赞 2
评论 0 · 赞 2
评论 0 · 赞 1
评论 0 · 赞 2
评论 0 · 赞 0
添加新评论56 条评论
2023-09-12 15:06
2022-12-28 11:10
2021-11-11 09:45
2021-11-11 09:45
2021-06-18 21:24
2017-05-15 11:11
2016-07-14 10:27
2016-04-27 10:07
2016-04-06 10:01
2015-07-08 11:53
2015-06-19 14:44
2015-06-18 20:53
2015-06-17 22:58
2014-12-15 12:40
2014-02-24 10:38
2014-01-24 08:13
2013-12-19 10:36
2013-12-09 15:50
2013-12-05 16:35
2013-12-05 12:08
2013-12-04 10:03
2013-12-03 09:14
2013-12-02 12:41
2013-11-29 13:17
2013-11-29 10:04
2013-11-29 00:39
2013-11-28 17:19
2013-11-28 10:02
2013-11-25 21:18
2013-11-25 11:45
2013-11-25 10:00
2013-11-20 14:43
2013-11-20 14:42
2013-11-19 17:47
2013-11-19 15:47
2013-11-17 09:22
2013-11-16 00:00
2013-11-15 10:12
2013-11-14 15:04
2013-11-14 11:15
2013-11-14 11:14
2013-11-13 17:39
2013-11-13 10:22
2013-11-13 10:16
2013-11-12 15:51
2013-11-12 13:25
2013-11-12 10:02
2013-11-12 09:12
2013-11-11 15:36
2013-11-11 12:34
2013-11-11 11:53
2013-11-09 15:10
2013-11-08 15:33
2013-11-08 14:00
2013-11-08 13:21
2013-11-08 11:07